

mysql学习笔记-锁篇
MySQL锁问题在数据库中,除了传统的计算资源(CPU,RAM,I/O)的争用外,数据也是一种许多用户共享的资源。如何保证数据并发一致性和有效性是数据库必须解决的问题。
MySQL锁概述MySQL的锁机制因不同引擎而异:
MyISAM和MEMORY存储引擎:采用表级锁。
InnoDB存储引擎:采用行级锁(默认),也支持表级锁。
MySQL的三种锁特性如下:
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,锁冲突概率高,并发度低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度小,锁冲突概率低,并发度高。
页面锁:开销和加锁时间介于表锁和行锁之间;会出现死锁;锁定粒度介于表锁和行锁之间,并发度一般。
MyISAM表锁查询表级锁争用情况12-- 查看锁争夺情况SHOW STATUS LIKE 'Table%';
MyISAM存储引擎写阻塞的例子12345678910111213-- 线程1操作LOCK TABLE film_text WRITE;-- 查询操作SELECT file_id, title FROM film_text WHERE fil ...

mysql学习笔记-优化篇
sql优化优化sql语句的一般过程
通过show status命令了解sql的执行频率
1234567891011121314151617181920212223show [global/session]status like Com_%;/*Com_xxx 表示每个 xxx 语句执行的次数,我们通常比较关心的是以下几个统计参数。 Com_select:执行 select 操作的次数,一次查询只累加 1。 Com_insert: 执行 INSERT 操作的次数, 对于批量插入的INSERT 操作, 只累加一次。 Com_update:执行 UPDATE 操作的次数。 Com_delete:执行DELETE 操作的次数。上面这些参数对于所有存储引擎的表操作都会进行累计。下面这几个参数只是针对InnoDB 存储引擎的,累加的算法也略有不同。 Innodb_rows_read:select 查询返回的行数。 Innodb_rows_inserted:执行INSERT 操作插入的行数。 Innodb_rows_updated:执行 UPDATE 操作更新的行数。 Innodb_ ...
一篇文章吃透Stream流
Java Stream引入在 Java 中,经常需要处理数组、Collection 等集合的操作,传统上我们会使用循环的方式来实现。然而,Java 8 引入了一种更加优雅和高效的方式——Stream API。Stream 允许我们以函数式编程的风格来处理数据序列(如集合、数组或 I/O 资源),它提供了声明式的数据处理方式,使代码更易读、更简洁,同时还能更好地利用多核处理器。
Stream 并不是一个数据结构,而是对数据进行计算的一种方式。它支持延迟执行(lazy evaluation),即只有在需要时才执行操作,这可以显著提高性能,尤其是在处理大型数据集时。此外,Stream 还支持并行处理,无需显式编写多线程代码即可利用多核 CPU。
接下来,我们将深入探索 Java Stream 的各个方面,包括它的创建、操作类型、流水线、并行处理以及实际应用场景。
创建 StreamStream 的创建方式多种多样,下面列出了一些常见的方法,并附上示例代码:
创建方式
描述
示例代码
从集合
使用集合的 stream() 方法
List<String> lis ...
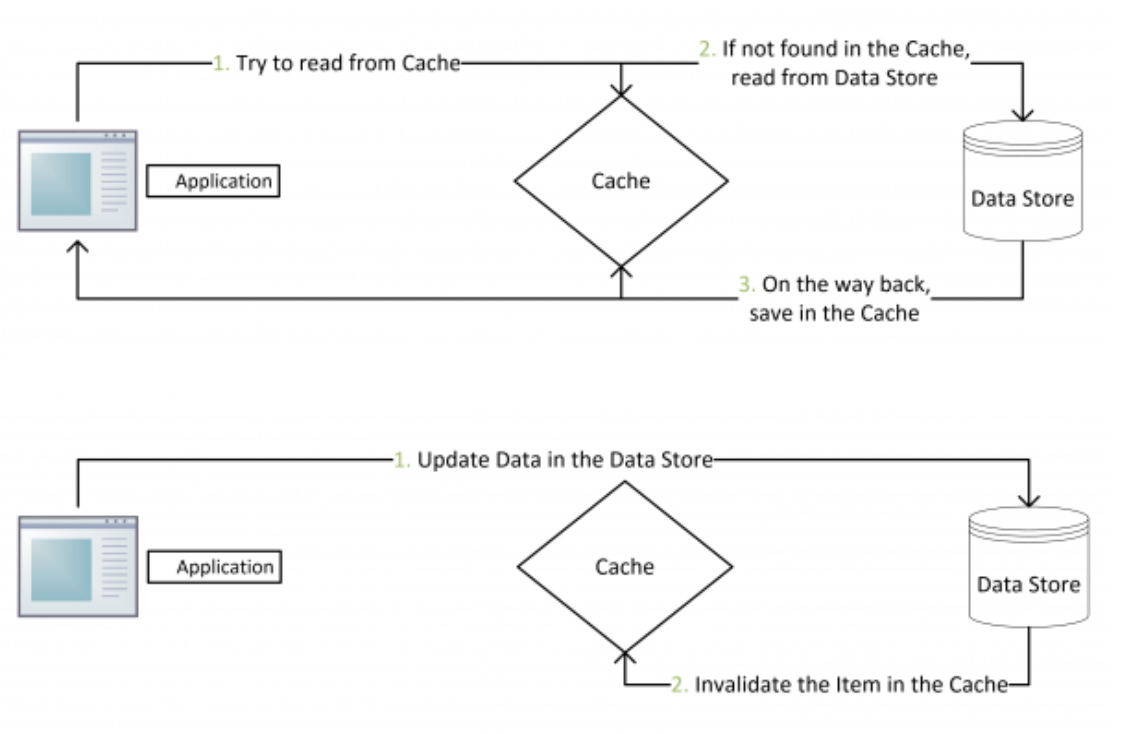
缓存一致性解决方案
Introduction我们知道使用缓存可以加快数据的访问速度,但是如何更新缓存也随之成为了问题。更新缓存有四种模式:
Cache Aside Pattern
Read/Write Through Pattern
Read Through
Write Through
Write Behind Caching Pattern
现在常见的解决思路是先删除缓存,然后再更新数据库,后续的操作会把数据装载到缓存中。
问题有两个操作,一个更新,一个查询操作,这两个是并发操作。更新操作先进行删除缓存,接下来查询操作发现没有数据,会从数据库中读取数据,然后放在缓存中,但是接下来更新操作会去进行更新数据库。于是缓存中的数据一直是脏数据。
Cache Aside Pattern具体的逻辑如下:
失效:先从 Redis 中读取数据,如果没有得到,就从数据库中读取数据,成功后,放入缓存中。
命中:应用程序从缓存中取出数据,然后返回。
更新:先把数据存入数据库中,成功后,再让缓存失效。
现在看一下如果一个更新操作,一个查询操作在并发情况下是否有问题。查询操作并不会去删除缓存中的数据,然后 ...
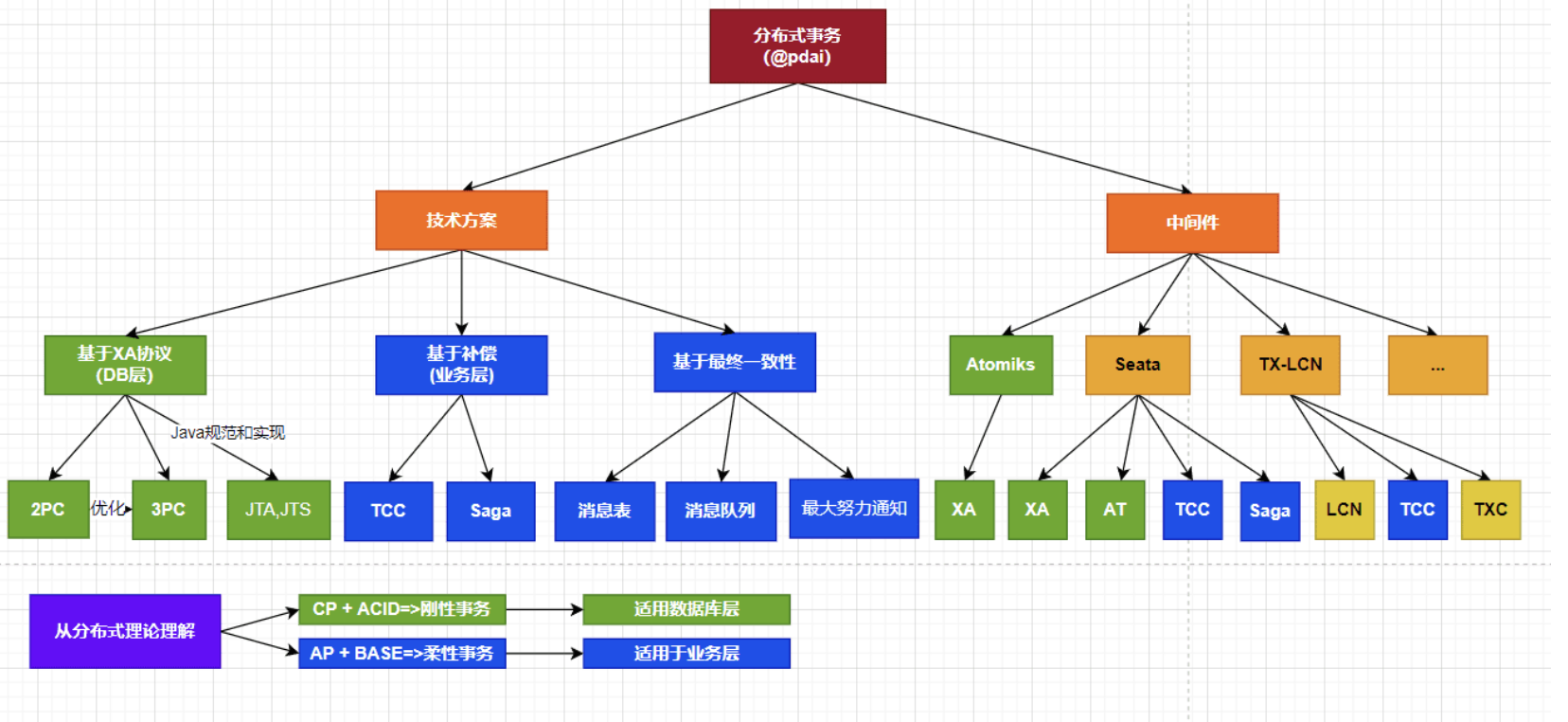
聊聊消息分布式事务之柔性事务
分布式事务分布式事务之体系梳理
通过 @pdai 总结的体系图,我们可以发现技术方案的选择可以分为以下几种:
基于 XA 协议(数据库层面):
适用于需要保证一致性和分区容错性的场景。
遵循 ACID 理论,通常称为刚性事务。
常见实现方式包括二阶段提交(2PC)和三阶段提交(3PC)。
基于补偿(业务层面):
适用于需要保证可用性和分区容错性的场景。
遵循 BASE 理论,通常称为柔性事务。
常见实现方式包括 TCC(Try-Confirm/Cancel)和 SAGA 模式。
基于数据一致性(柔性事务):
通过最终一致性来实现。
使用消息表(本地消息表)和消息队列来实现最终一致性。
通过最终努力通知对消息队列进行进一步优化。
根据 CAP 理论,一致性、可用性和分区容错性,我们可以总结出:
如果需要保证 CP(一致性和分区容错性),同时遵循 ACID 理论,这就是刚性事务,通常需要遵循 XA 协议。
如果需要保证 AP(可用性和分区容错性),同时遵循 BASE 理论,这就是柔性事务,通常通过业务层的 TCC+SAGA 或最终一致性来实现。
分布式事 ...
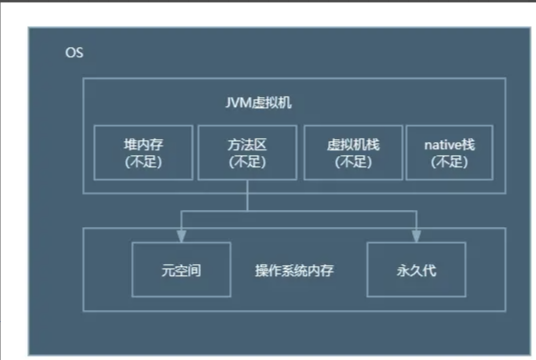
JVM调试排错--OOM
常见的内存溢出问题(内存和MetaSpace内存)
常见的内存溢出问题有,内存和metaspace内存
Java堆内存溢出Java堆内存溢出有两种形式的错误:
OutOfMemoryError: Java heap space
OutOfMemoryError: GC overhead limit exceeded
OutOfMemoryError: Java heap space在Java堆中不断地创建对象,并且GC-Roots到对象之间存在引用链,这样JVM就不会回收对象。
123456public static void main(String[] args) { List<Integer> list = new ArrayList<>(); while (true) { list.add(1); }}
OutOfMemoryError: GC overhead limit exceededGC overhead limit exceed检查是Hotspot VM 1.6定义的一个策略,通过统计G ...
架构高并发--降级与熔断
引入
服务依赖之间导致错误
当用户请求 A、P、H、I 四个服务获取数据时,在正常流量下系统稳定运行,如果某天系统进来大量流量,其中服务 I 出现 CPU、内存占用过高等问题,结果导致服务 I 出现延迟、响应过慢,随着请求的持续增加,服务 I 承受不住压力导致内部错误或资源耗尽,一直不响应,此时更糟糕的是其他服务对 I 有依赖,那么这些依赖 I 的服务一直等待 I 的响应,也会出现请求堆积、资源占用,慢慢扩散到所有微服务,引发雪崩效应。
基本的容错模式主动超时:Http请求主动设置一个超时时间,超时就直接返回,不会造成服务堆积
限流:限制最大并发数
熔断:当错误数超过阈值时快速失败,不调用后端服务,同时隔一定时间放几个请求去重试后端服务是否能正常调用,如果成功则关闭熔断状态,失败则继续快速失败,直接返回。(此处有个重试,重试就是弹性恢复的能力)
隔离:把每个依赖或调用的服务都隔离开来,防止级联失败引起整体服务不可用
降级:服务失败或异常后,返回指定的默认信息
服务降级
由于爆炸性的流量冲击,对一些服务进行有策略的放弃,以此缓解系统压力,保证目前主要业务的正常运行。它主要是针对非正常 ...
Java垃圾回收器之G1详解
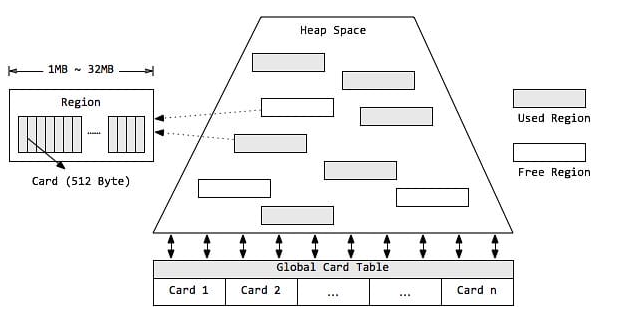
G1垃圾回收器概述G1垃圾回收器是在Java7 update 4之后引入的一个新的垃圾回收器。G1是一个分代的,增量的,并行与并发的标记-复制垃圾回收器。它的设计目标是为了适应现在不断扩大的内存和不断增加的处理器数量,进一步降低暂停时间(pause time),同时兼顾良好的吞吐量。G1回收器和CMS比起来,有以下不同:
G1垃圾回收器是compacting的,因此其回收得到的空间是连续的。这避免了CMS回收器因为不连续空间所造成的问题。如需要更大的堆空间,更多的floating garbage。连续空间意味着G1垃圾回收器可以不必采用空闲链表的内存分配方式,而可以直接采用bump-the-pointer的方式;
G1回收器的内存与CMS回收器要求的内存模型有极大的不同。G1将内存划分一个个固定大小的region,每个region可以是年轻代、老年代的一个。内存的回收是以region作为基本单位的;
G1还有一个及其重要的特性:软实时(soft real-time)。所谓的实时垃圾回收,是指在要求的时间内完成垃圾回收。“软实时”则是指,用户可以指定垃圾回收时间的限时,G1会努力在这个 ...
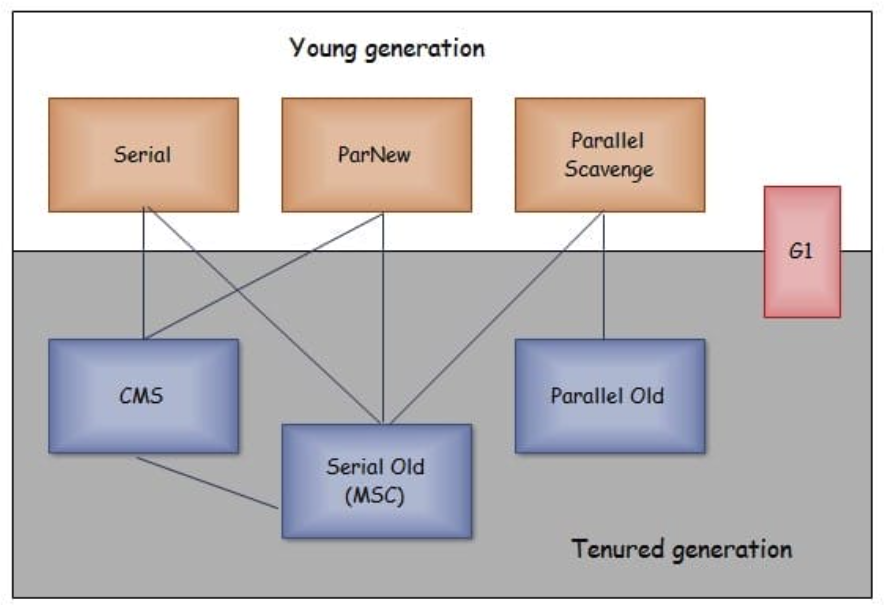
理解GC
垃圾收集主要是针对堆和方法区进行;程序计数器、虚拟机栈和本地方法栈这三个区域属于线程私有的,只存在于线程的生命周期内,线程结束之后也会消失,因此不需要对这三个区域进行垃圾回收。
判断一个对象是否可以被回收
引用计数法1234567891011public class ReferenceCountingGC { public Object instance = null; public static void main(String[] args) { ReferenceCountingGC objectA = new ReferenceCountingGC(); ReferenceCountingGC objectB = new ReferenceCountingGC(); objectA.instance = objectB; objectB.instance = objectA; }}
可达性分析通过 GC Roots 作为起始点进行搜索,能够到达到的对象都是存活的 ...
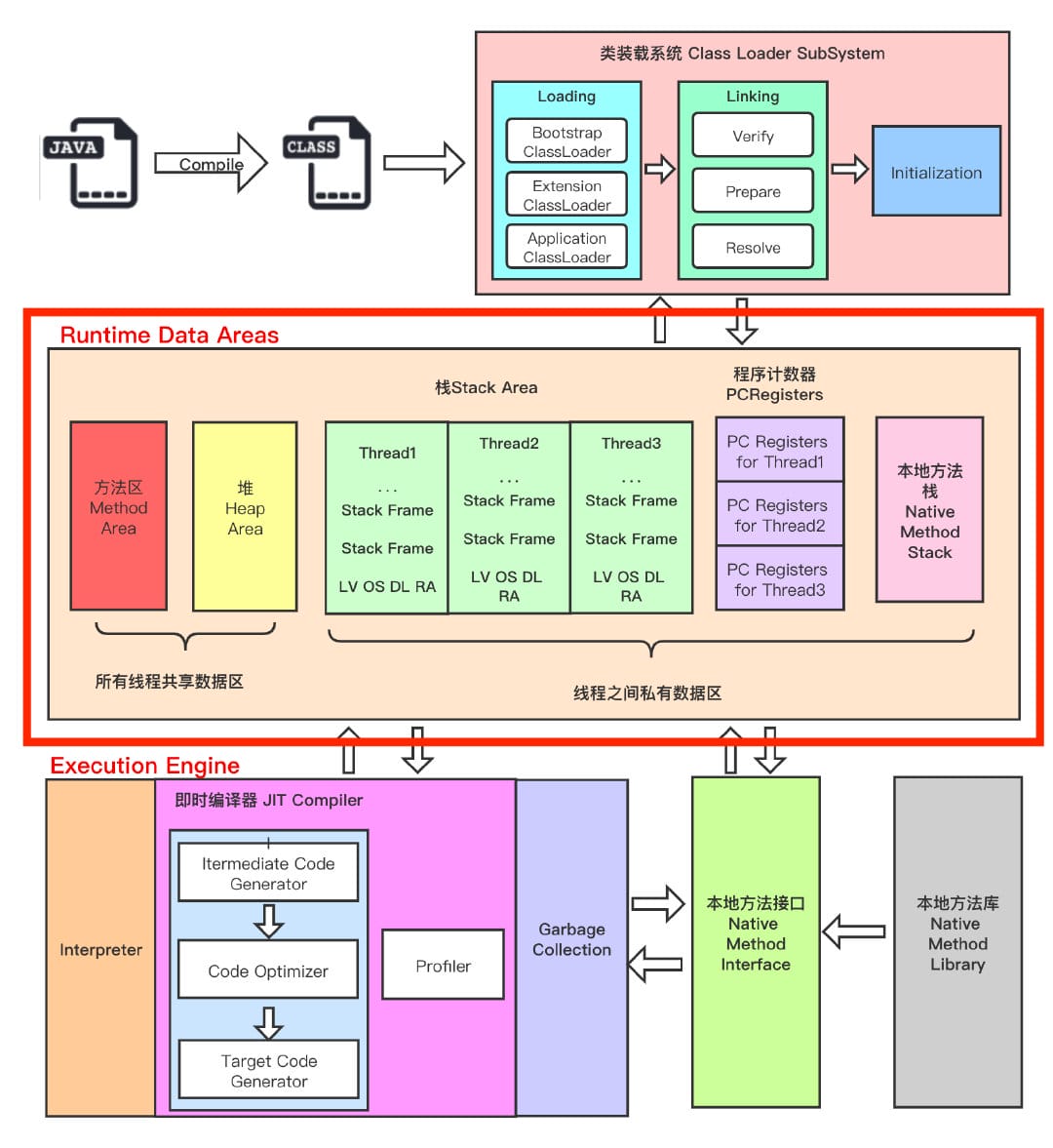
深入JVM(上)
jvm是java中最为核心的部分,现在对于以前学习的细节没有学习到的点做一个概括
首先借用一个@pdai佬的思维导图来做一下知识引入。我的jvm篇的知识按照以下的思路进行:
JVM类加载
JVM的内存结构
JVM相关的JMM
JVM的GC
最后按照情况写一下JVM的排错调优
类的加载类的生命周期类加载的过程包括了加载、验证、准备、解析、初始化五个阶段。在这五个阶段中,加载、验证、准备和初始化这四个阶段发生的顺序是确定的,而解析阶段则不一定,它在某些情况下可以在初始化阶段之后开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)。另外注意这里的几个阶段是按顺序开始,而不是按顺序进行或完成,因为这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。
类的加载:查找并加载类的二进制数据
我们从上图可以得知到的信息有:
通过一个类的全限定名来获取其对应的二进制数据流
将这个字节流所代表的数据存储结构转换为方法区的运行时数据结构
在Java中的堆中创建一个代表这个类的lang.class对象,作为对方法区这些数据的访问入口
连接验证:确保被 ...