零拷贝技术与IO多路复用
ZeroCopy(零拷贝技术)为什么要有DMA技术
我们可以过程中的每一步都需要cpu的参与当我们引进dma技术后我们再来看整个流程
现在将原来的从磁盘控制器缓冲区搬运到pagecache的过程全部交给dma来完成
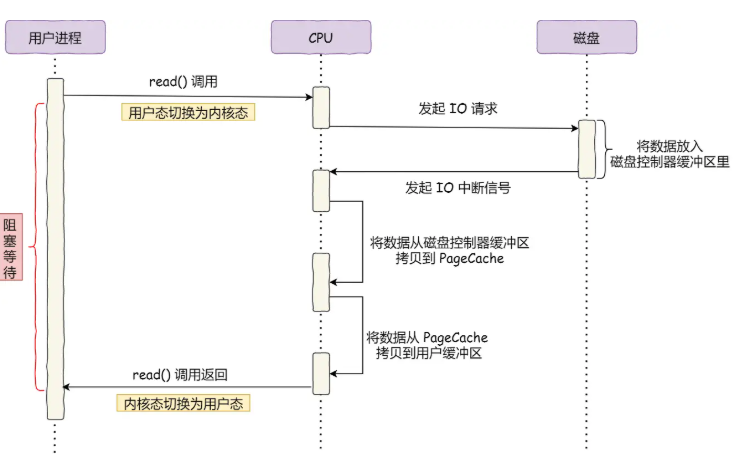
传统的文件传输功能我们假设如果服务端需要文件传输的功能,我们会明白,首先从磁盘上讲文件读取出来,然后通过网络协议发送给客户端
传统的io的 工作方式是数据读取和写入是从用户空间到内核空间来回复制,而内核空间是通过操作系统的io接口从磁盘读取和写入
我们可以发现一共发生了四次拷贝,其中两次dma拷贝,一共四次上下文切换
我们可以来看一下如何实现零拷贝
实现零拷贝的方式有两种
mmap + write
sendfile
mmap前面我们知道了read()系统调用会把内核缓冲区的数据拷贝到用户缓冲区于是为了减少这一步的开销,我们可以使用mmap()来替代read()函数,这样可以减少一次拷贝
mmap使用的原理是将用户缓冲区与内核缓冲区进行共享,使用映射的方法,这样操作系统与系统内核空间就不需要任何数据拷贝的操作
此时系统是四次上下文切换,三次拷贝
sendfile在l ...
Kafka PageCache原理
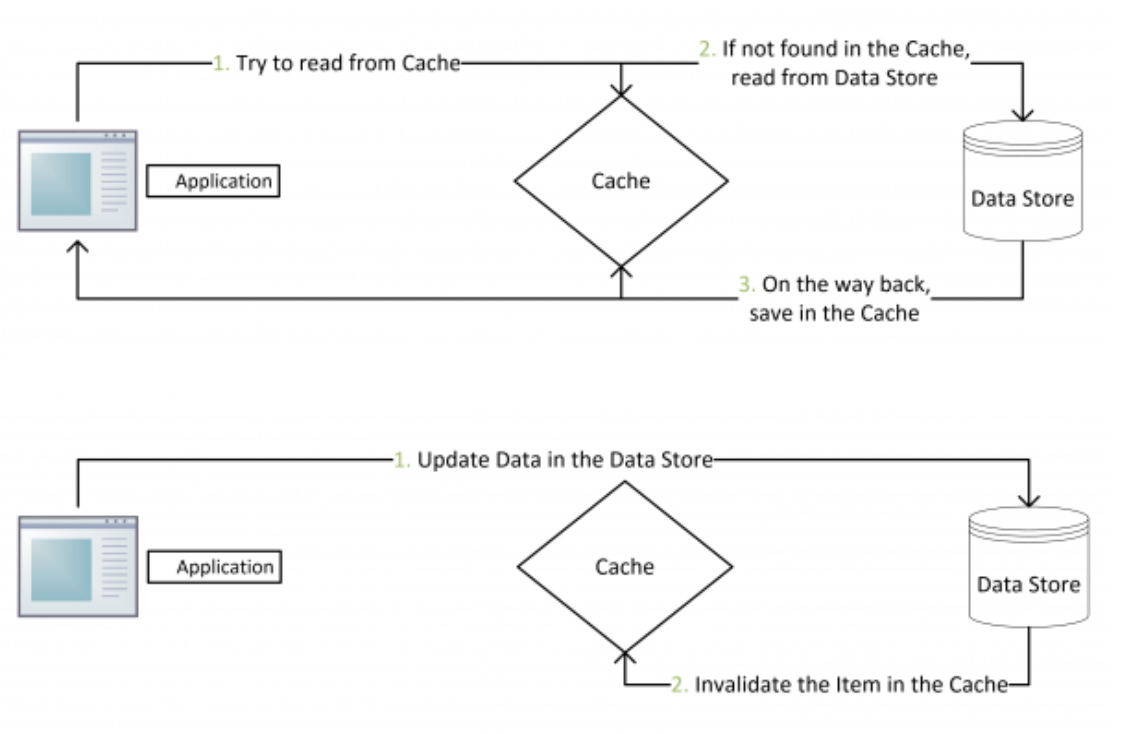
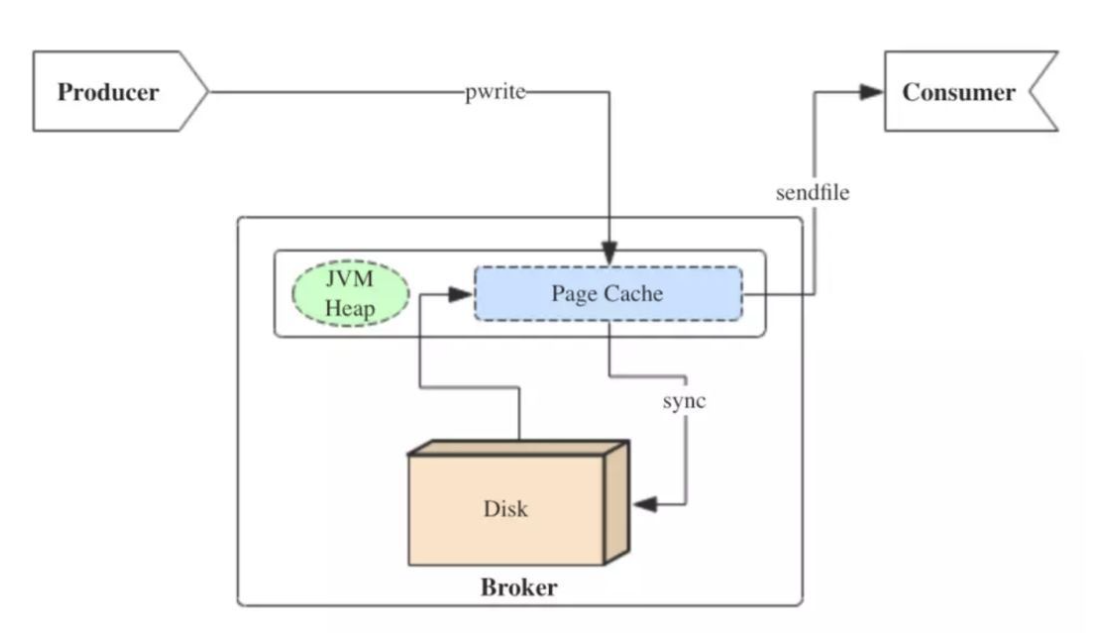
pagecache回顾我的zerocopy的文章,我们可以发现,其中第一步都是需要先把磁盘文件数据拷贝到内存缓冲区,这个内存缓冲区就是pagecache
由于零拷贝使用到了pagecache,所以零拷贝技术的性能得到了进一步的提升。
读写磁盘的速度相比于读写内存的速度慢太多,所以我们应该把读写磁盘替换成读写内存。
但是我们知道读写内存具有局限性,pagecache就使用了预读的功能,读磁盘数据的时候,如果read方法每次只读前32k的内容,但是内核会把32~64kb的字节也读取出来
这时候,pagecache的优点有两个:
缓存最近呗访问的数据
预读功能
kafkakafka重度依赖于底层操作系统的pagecache的功能
kafka为什么不自己管理缓存,而是使用pagecache,理由如下:
JVM中一切皆对象,数据的对象存储会带来所谓object overhead,浪费空间;
如果由JVM来管理缓存,会受到GC的影响,并且过大的堆也会拖累GC的效率,降低吞吐量;
一旦程序崩溃,自己管理的缓存数据会全部丢失。
我们来看一下kafka的两大核心组件如何引入cache的功能的
...
深入理解Spring--aop篇
AOPSpring 框架通过定义切面, 通过拦截切点实现了不同业务模块的解耦,这个就叫面向切面编程 - Aspect Oriented Programming (AOP)
AOP在Spring中的作用
横切关注点:跨越应用程序多个模块的方法或功能。即是,与我们业务逻辑无关的,但是我们需要关注的部分,就是横切关注点。如日志 , 安全 , 缓存 , 事务等等 ….
切面(ASPECT):横切关注点 被模块化 的特殊对象。即,它是一个类。
通知(Advice):切面必须要完成的工作。即,它是类中的一个方法。
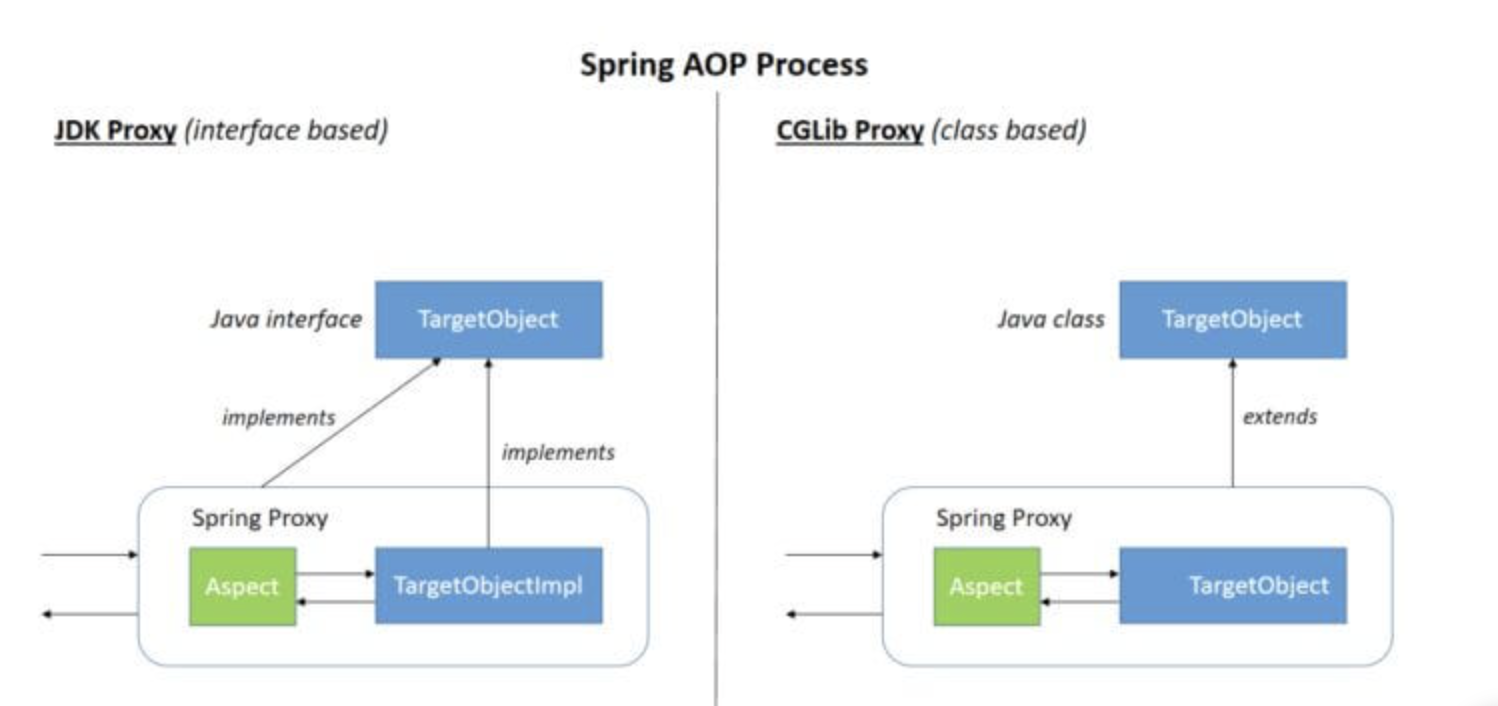
目标(Target):被通知对象。
代理(Proxy):向目标对象应用通知之后创建的对象。
切入点(PointCut):切面通知 执行的 “地点”的定义。
连接点(JointPoint):与切入点匹配的执行点。
AOP的实现方式通过Spring API实现1234567//首先实现一个接口类public interface UserService { public void add(); public void delete(); public void ...
深入理解 Spring 核心概念
深入理解 Spring 核心概念深入浅出 Spring 自动装配原理从 @SpringBootApplication 作为入口,我们可以看到它包含三个核心注解:
123@SpringBootConfiguration@EnableAutoConfiguration@ComponentScan
接下来详细解释每个注解的作用。
1. @SpringBootConfiguration进入 @SpringBootConfiguration 后的内容如下:
123456@Target({ElementType.TYPE})@Retention(RetentionPolicy.RUNTIME)@Documented@Configurationpublic @interface SpringBootConfiguration {}
其实它只是声明 SpringApplication 也是一个配置类。
2. @ComponentScan12345678910@AliasFor("value")String[] basePackages ...
浅入深出kafka--基础篇
kafkakafka的基本结构
message: key+value
key:讲key值路由到指定的partition中,从而保证key相同的message写入同一partition中
value: 传递真正的值
topic:producer和consumer在写入之前进行约定
topic可以看成一个message的通道,连接多个producer和consumer
partition: 在topic中进行了进一步的拆分,将topic分为了至少一个partition
当message被producer push到partition中的时候,会被分配一个offset编号(通过offset编号就可以保证了一个partion中的消息是有序的)
同时kafka中的一个topic的横向扩展能力是通过partition实现的。
同一 topic 的不同 partition 会分配到不同的物理机上,partition 是 topic 横向扩展的最小单位,一个 partition 中存储的这一组有序 message 没法存储到多台机器上。
broker:
(kafka提 ...
paypal支付接入
由于国内的支付方式都需要商家资质,沙盒环境都不能使用,因此在这里记录一下paypal的接入过程
前提准备去开发环境获取clientId以及token接着去curl生成一个产品
1234567891011curl -v -X POST https://api-m.sandbox.paypal.com/v1/catalogs/products -H "Content-Type: application/json" -H "Authorization: Bearer ACCESS-TOKEN" -H "PayPal-Request-Id: REQUEST-ID" -d '{ "name": "Video Streaming Service", "description": "A video streaming service", "type": "SERVICE", &qu ...
简析分期支付实现--优化篇(2)
回顾上一篇聊到了如何去保证转账功能的唯一性,和浅谈了一下加入了cas提升了转账行为的效率,这期我们来谈一谈在延时队列的任务加入后我们做了什么。
我们预估的系统的使用人数如果是一百万的话,如果每个人在使用这个平台完成了五笔合同,(都是按月转账),那么系统每个月需要处理的转账到达五百万笔,那么平均每秒需要完成的交易金额在19290笔左右,这时候我们单纯的开辟一个线程池去直接消费,线程池压力会非常大,同时使用线程池也不能够支持削峰,面对突然激增的活动肯定会出现故障,因此我在这个过程中牺牲了一定的转账的准确性。
实现在我的实现中一共设计了三个消费主题
@KafkaListener(topics = "contract-scheduled", groupId = "contract-group")延时队列发送过来的消息进行消费
@KafkaListener(topics = "contract-scheduled-retries", groupId = "contract-group-retries")如果消费失败 ...
简析分期支付实现-优化篇
回顾在上篇文章中我们谈到了如何实现一个分期支付的原理,大体上是用户点击支付按钮后会先去判断用户的余额和合同金额是否足够去进行支付然后去发送到消息队列去扣减余额
问题我将消息发送到消息队列去消费的原因是为了提高系统的吞吐量和同时使用异步的操作防止阻塞系统,但是又如下的几个问题:
首先就是是否需要保证消息的顺序读写
其次就是我们是否消息重复怎么解决,如何保证幂等性
如何提高消费者的消费速率
消费失败了怎么办(消息丢失)
调用多个微服务为什么不使用分布式事务,为什么使用消息队列保证最终一致性
当然这些都是我们后面需要探讨的,现在我们要进行探讨的是为什么需要使用redission分布式锁来防止同时修改
同一个商家会出问题
实现如果我们不使用kafka进行拉高消费速率的话,我们可能不会遇到这个情况,因为延迟队列会保证只有一个线程更改资源
我们注意到
在底下的发送的操作中我们使用了一个async的方法去进行处理转账在这里我开辟了一个核心线程数为十的线程池充当消费者
接下来我们来看异步的过程处理了哪些任务
判断是否是热点用户12345if(hotSpotAccountListen ...
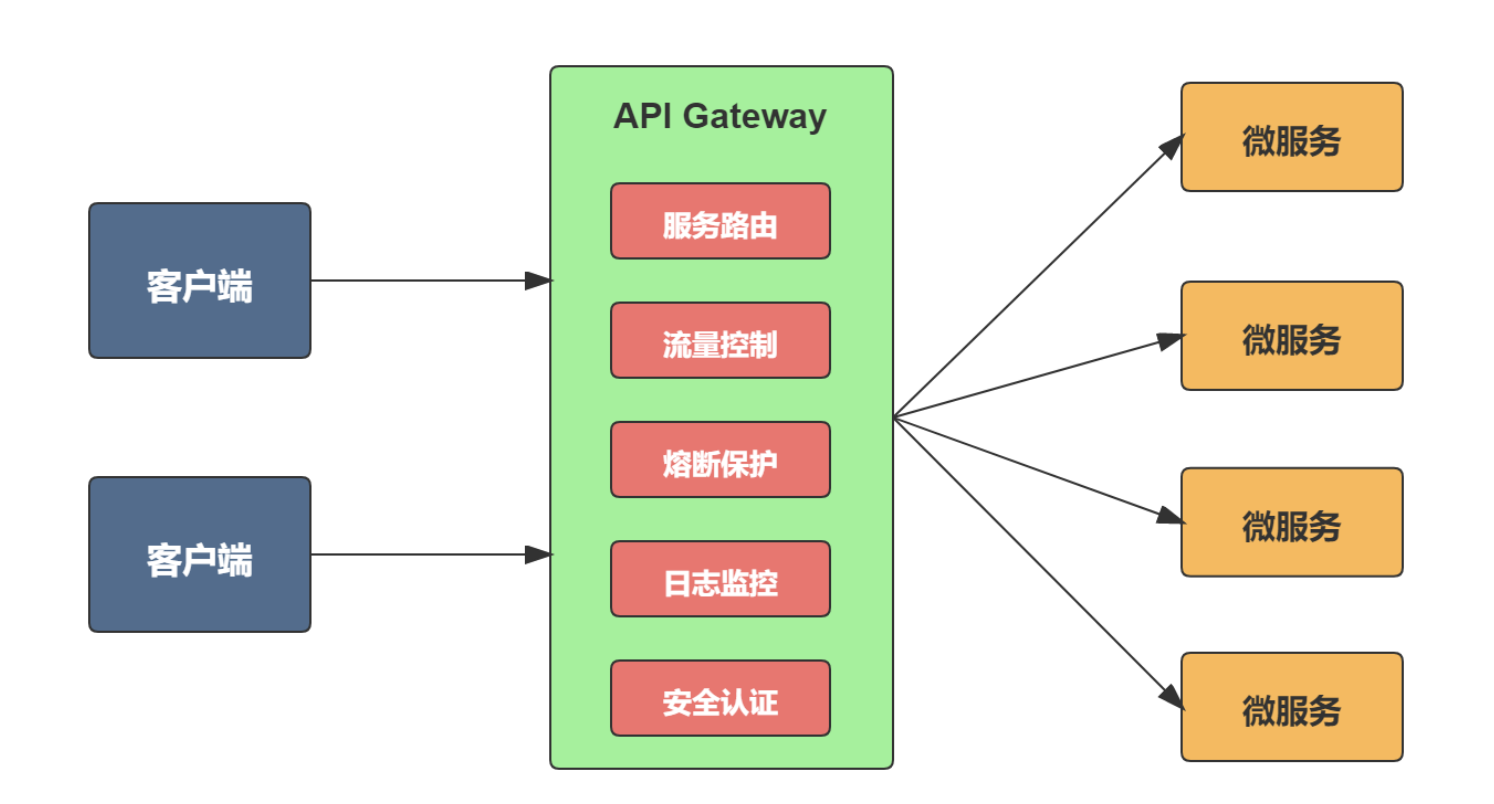
简析SpringCloud网关
为什么需要网关什么是服务网关传统的单体架构中只需要开放一个服务给客户端调用,但是微服务架构中是将一个系统拆分成多个微服务,如果没有网关,客户端只能在本地记录每个微服务的调用地址,当需要调用的微服务数量很多时,它需要了解每个服务的接口,这个工作量很大。
微服务网关的基本功能
对比一下不同的网关这里对比一下gateway 和 zuulgateway 网关:功能强大丰富,性能好,官方基准测试 RPS (每秒请求数)是Zuul的1.6倍,能与 SpringCloud 生态很好兼容,单从流式编程+支持异步上也足以让开发者选择它了。
(4)Zuul 2.x:性能与 gateway 差不多,基于非阻塞的,支持长连接,但 SpringCloud 没有集成 zuul2 的计划,并且 Netflix 相关组件都宣布进入维护期,前景未知。
实践如何集成在项目中
在 Spring Cloud Gateway 中,我通过自定义 Zuul 过滤器 LoginFilter 实现了路由鉴权。LoginFilter 继承自 AbstractPreZuulFilter,属于前置过滤器,在请求路由之前执行鉴权逻辑。以下是实 ...
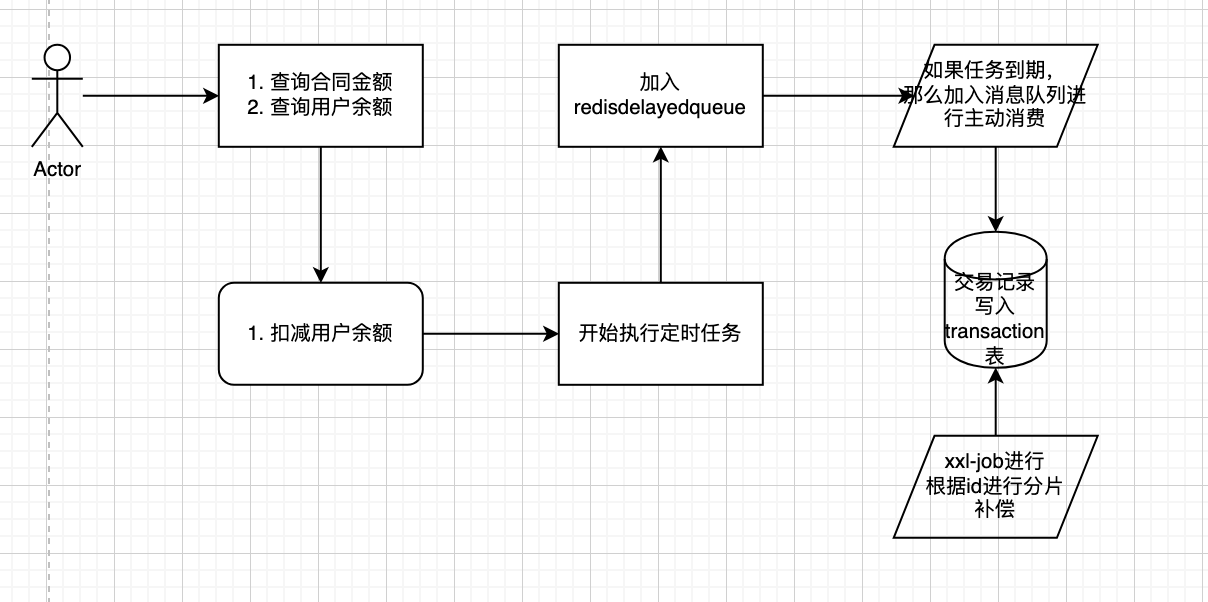
浅析分期支付的实现
场景在我的项目中,有遇到一个需要定期给用户转账的场景,但是最开始的想法是使用spring schduled来进行做定时任务,但是由于做逻辑的时候发现如果使用schduled来进行延迟性比较大,最后在网上查阅资料后发现可以使用redis的delayed queue来做定时任务,但是redis只能在单机节点上进行,如果在分布式场景下会导致重复消费,因此使用了redission来进行实现,同时在使用redission后为了保证交易的准确性,加入了xxl-job来做分布式分片广播定时任务来确保交易的完整性
实践
在使用redission的时候需要实现两个队列
12RBlockingQueue<T> rBlockingQueue = redissonClient.getBlockingQueue(queueName);RDelayedQueue<T> delayedQueue = redissonClient.getDelayedQueue(rBlockingQueue);
第一个阻塞队列是添加已经到时间的资源第二个是一个延迟队列接受传入的资源,并且进行到点弹出
启 ...