浅析分期支付的实现
场景
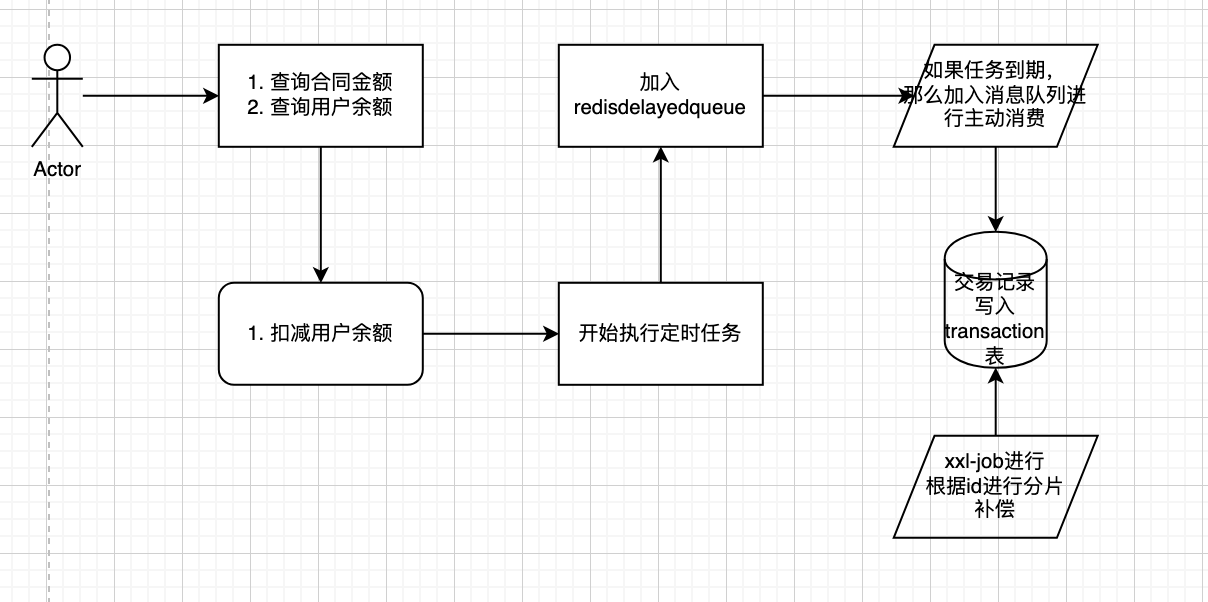
在我的项目中,有遇到一个需要定期给用户转账的场景,但是最开始的想法是使用spring schduled来进行做定时任务,但是由于做逻辑的时候发现如果使用schduled来进行延迟性比较大,最后在网上查阅资料后发现可以使用redis的delayed queue来做定时任务,但是redis只能在单机节点上进行,如果在分布式场景下会导致重复消费,因此使用了redission来进行实现,同时在使用redission后为了保证交易的准确性,加入了xxl-job来做分布式分片广播定时任务来确保交易的完整性
实践
- 在使用redission的时候需要实现两个队列
1 | RBlockingQueue<T> rBlockingQueue = redissonClient.getBlockingQueue(queueName); |
第一个阻塞队列是添加已经到时间的资源
第二个是一个延迟队列接受传入的资源,并且进行到点弹出
- 启动一个监听延迟队列的任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20RBlockingQueue<T> queue = redissonClient.getBlockingQueue(listenerName);
Thread thread = new Thread(() -> {
logger.info("启动监听队列线程" + listenerName);
while(true) {
try {
//用于从阻塞队列获取并且移除对头元素
T t = queue.take();
logger.info("获取到队列线程:{},获取到队列值{}", listenerName, t);
new Thread(() ->{
taskEventListenerEntry.invoke(t);
}).start();
} catch (InterruptedException e) {
logger.warn("监听到线程错误",e);
try {
Thread.sleep(10000);
} catch (InterruptedException ex) {
}
}
}
}); - 如果take后数据后那么就加入对应的监听队列的invoke方法我们可以注意到我们将定时任务执行的任务发送到了kafka进行消费,这里我们为了不阻塞任务的执行选择异步去进行消费
1
2
3
4
5
public void invoke(ContractScheduledRequest contractScheduledRequest) {
logger.info("fulfill contract, contractId:{}, merchantId:{}", contractScheduledRequest.getContractId(), contractScheduledRequest.getMerchantId());
kafkaTemplate.send(TOPIC, contractScheduledRequest);
}
同时我们为了解决如果转账失败我们应该怎么办,我们需要引入xxl-job,但是有一个问题就是如果我们为什么选择xxl-job,不选择spring scheduler,为了方便分布式环境使用,为什么我们要在补偿的时候选择分片广播呢,因为我们可以发现,在redis delayed queue中我们使用的是主动拉的模式,我们不需要去做重复消费的问题,而在分布环境中我们被动扫描的话需要解决重复消费的问题,因此需要引入分片的做法。同时如果发生故障,我们应该需要支持故障转移。
xxl-job
使用起来很简单,配好config后添加一个handler就可以
1 | // 当前分片 |
Q&A
为什么转账的过程放在kafka中?
考虑到转账任务的数量比较大,不应该阻塞在转账阶段,介于Kafka的高吞吐量以及kafka的并发处理能力较大,同时kafka支持消息持久化,即使系统发生故障也不会消失。
kafka进行处理会降低转账速度吗?如何应对
会,但也比阻塞take的操作好,同时,我的建议是到期转账的时候可以在发送一个消息给user,先告知转账已经启动,让转账系统进行流转。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 wechat
wechat- Alipay


Related Articles
Comment
WalineFacebook Comments