浅入深出kafka--基础篇
kafka
kafka的基本结构
message: key+value
key:讲key值路由到指定的partition中,从而保证key相同的message写入同一partition中
value: 传递真正的值
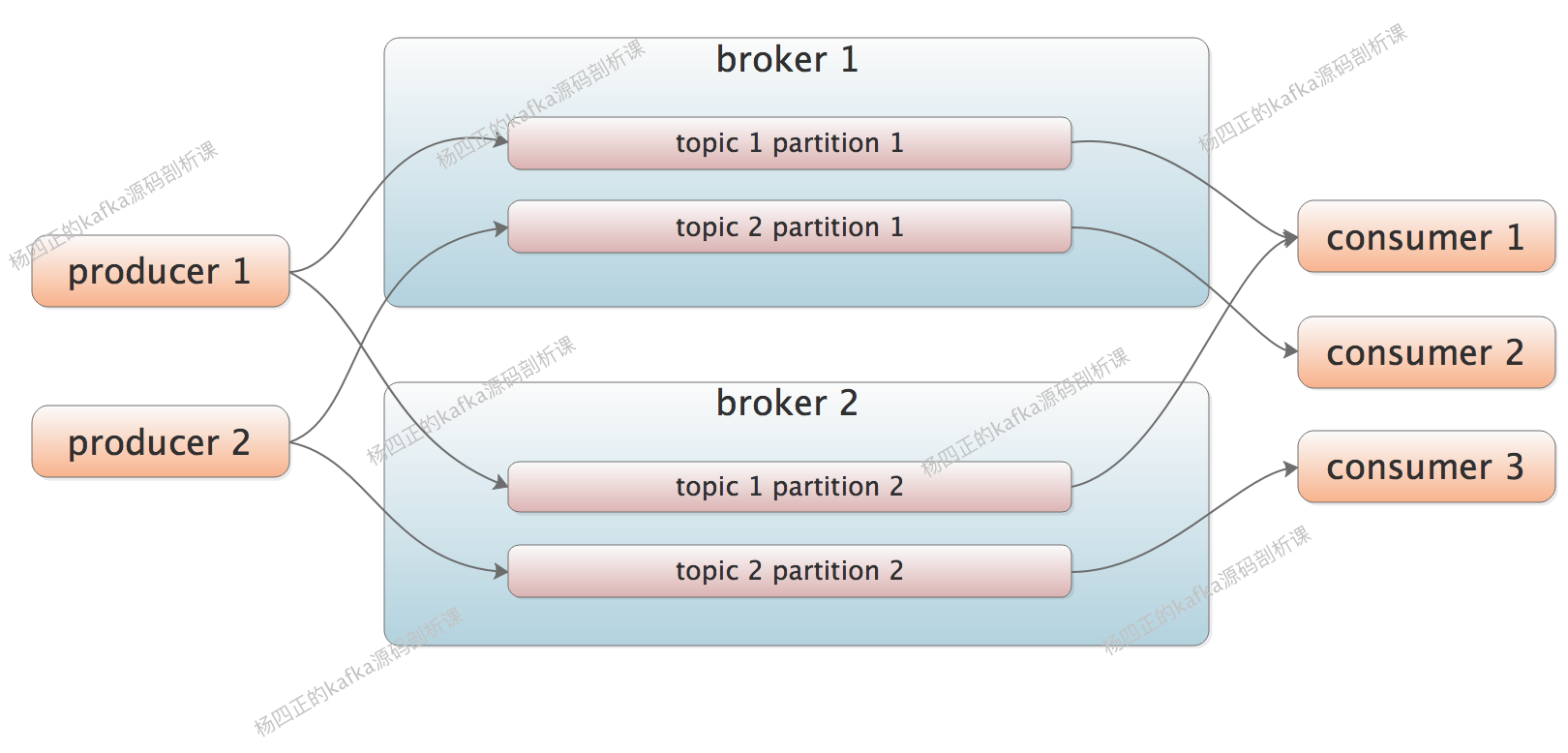
topic:producer和consumer在写入之前进行约定
- topic可以看成一个message的通道,连接多个producer和consumer
partition: 在topic中进行了进一步的拆分,将topic分为了至少一个partition
当message被producer push到partition中的时候,会被分配一个offset编号(通过offset编号就可以保证了一个partion中的消息是有序的)
同时kafka中的一个topic的横向扩展能力是通过partition实现的。
同一 topic 的不同 partition 会分配到不同的物理机上,partition 是 topic 横向扩展的最小单位,一个 partition 中存储的这一组有序 message 没法存储到多台机器上。
broker:

(kafka提高吞吐量的方法)提高partition和broker进行提高吞吐量
主要的职责:1. 接受producer push过来的message 2. 处理consumer请求 3. 处理集群其他的broker的请求
log:
partition逻辑上实际上对应着一个log,kafka实际上写入message到partition中的log中(log对应一个磁盘上的文件夹),log文件夹下逻辑上又分为多个segment文件
当message在写入的时候实际上写入的是最新的segment文件和index文件,当segment进行膨胀过大的时候会进行创建一个新的segment进行写入,未了避免过大实际上在写入segement的时候是顺序写入
index文件是segment的一个稀疏索引,提高索引速度。
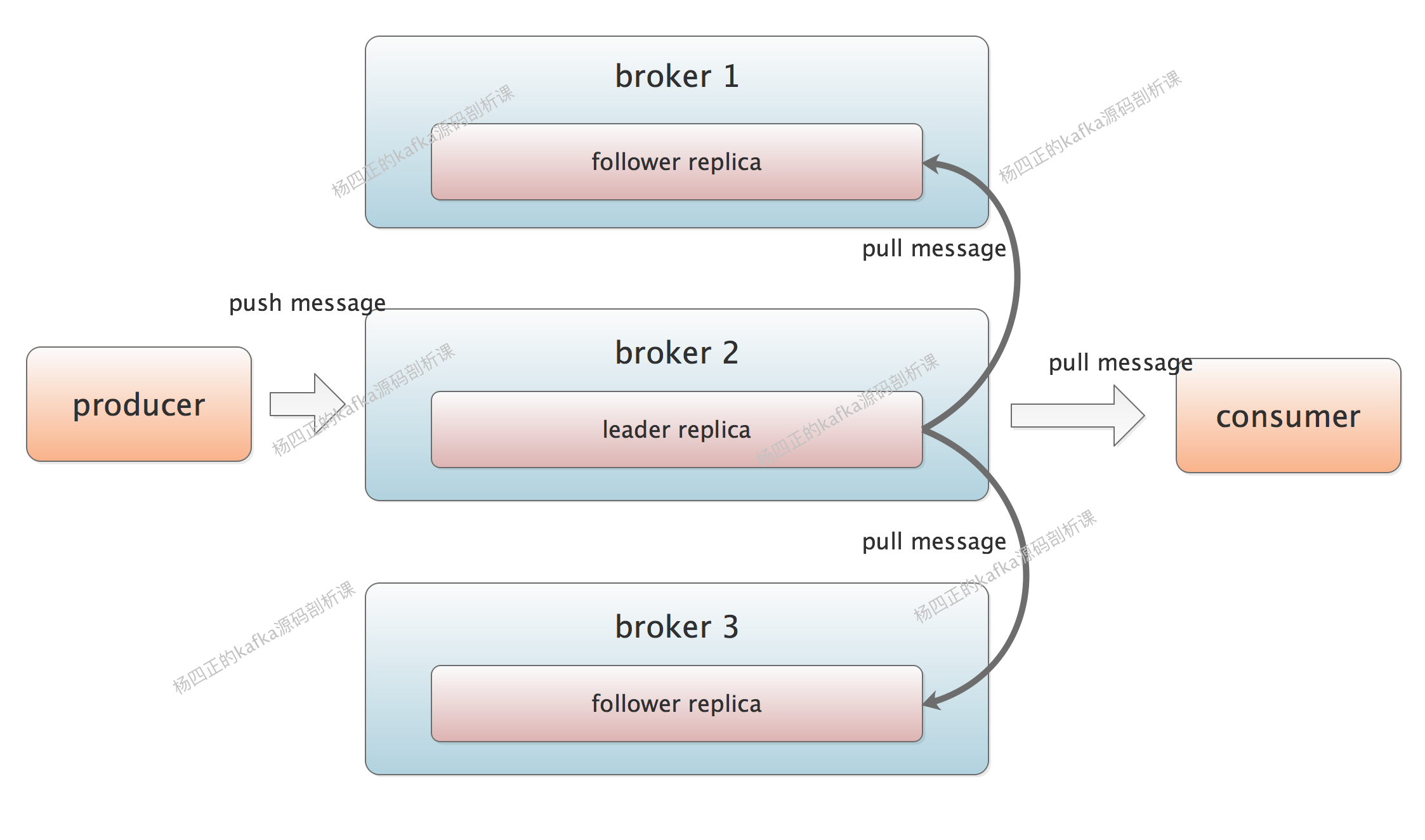
replica:
一个partition会有多个replica,有一个是leader,其他的都是follower,所有的读写请求都是有leader处理,其余的定期进行拉入更新自己的log
使用replica保证了分布式系统的可用性,保证数据完整性和安全性,也叫备份
如果其中的一个broker宕机,那么会进行选举新的leader replica。
同一partition中的replica相同
ISR集合(In-Sync Replic)
表示一个replic集合
replica所在的broker必须与zookeeper保持连接
replica中最后一条message的offset与leader replica中的最后一条message的offset之间的差值不能超出指定的阈值
如果长时间没有进行数据同步,会进行踢出ISR集合
同时会进行回追,如果message的offset小于leader replica的差值阈值时会重新加入ISR集合中
Highwatermark,Log and Offset
consumer只能消费HW标记之前的值
HW值由leader replica进行管理
LEO是所有的replica都有的一个标记,用于记录当前的replica的最后一个offset值
HW的值为所有的replica的最小的LEO值
Retition Policy & Log compaction
无论message是否被consumer消费,kafka都会长时间保留message信息,这种通过retition(保留策略进行保证)同时可以针对所有的topic进行执行,或者针对特定的topic进行执行
默认的有两种:
根据message保留的时长进行清理,如果超过阈值我们就可以进行清理
当topic的log大于一个阈值之后,我们就可以开始后台线程删除最旧的message
log Compaction:我们只关心value,我们会将相同的key的message进行合并,保留最新的value值
controller:
会选举一个broker作为controller,来管理partition下replica的状态以及坚挺zookeeper的数据的变更
所有的broker会进行监听controller的状态,如果宕机会进行重新选举
consumer:
consumer中维护了一个offset信息,用来记录当前consumer消费到了partition的哪个位置
同时减轻了broker维护consumer的压力,如果broker出现故障时,就会导致消息丢失,consumer可以正确的消费
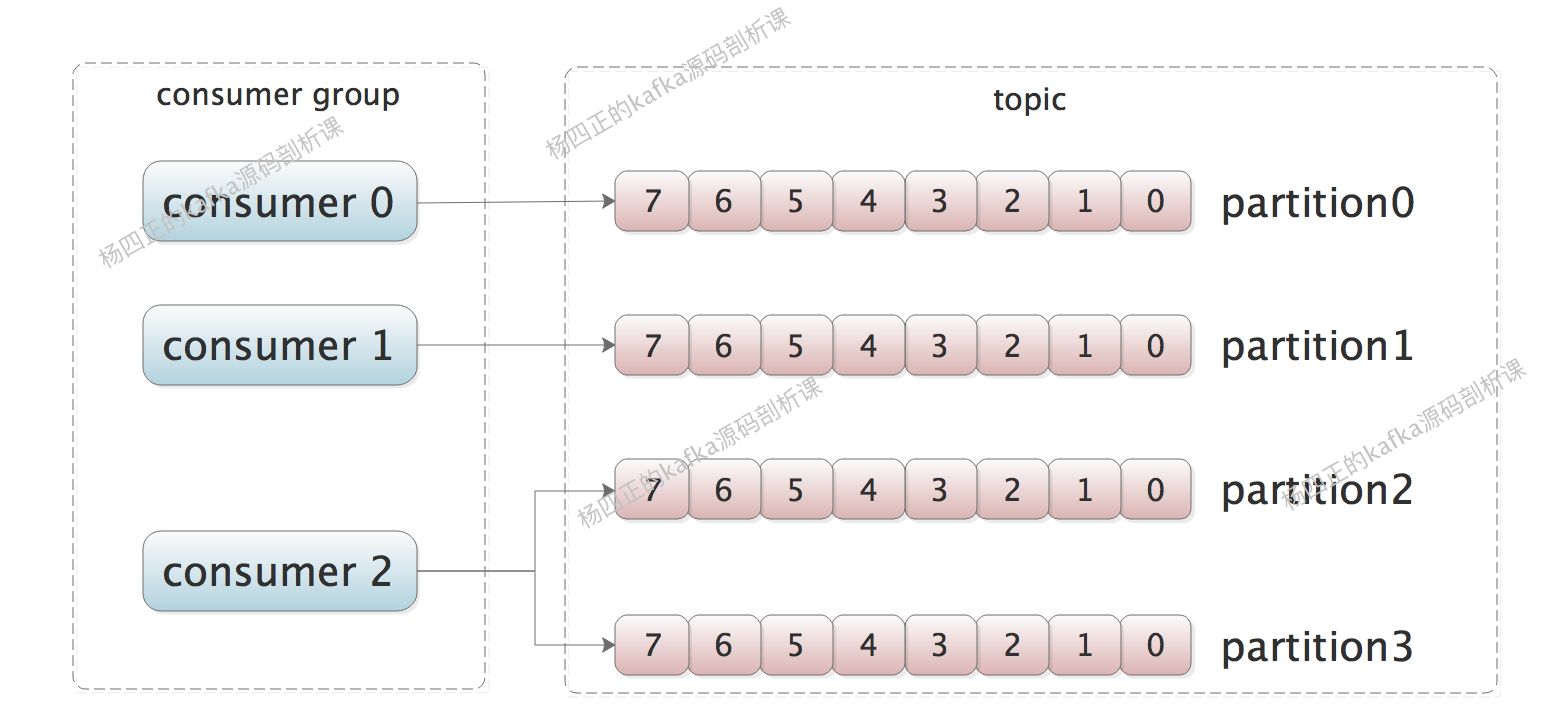
consumer group
Consumer group是消费message的基本单位
如果要实现多播我们可以将一个consumer作为一个consumer group
如果想要实现独占消费我们可以将目标topic的consumer放在一个consumer group 中,我们就可以保证每个partition中只有一个consumer消费
如果consumer的消费能力不够时,再添加一个consumer会进行重新映射
消费顺序
kafka通过partition 和consumer group保证消费顺序
生产者侧: 通过key将所有消息映射到同一个确定的分区上(保证相同的消息会被路由到同一个分区)
消费者侧: 保证消费者组内只有一个消费者实例进行消费,才能保证分区的顺序消费。(可以通过设置消费者组内的并发度小于分区数来实现)
多分区下的消费顺序的保证
可以使用分区器保证,将相同的业务标识的消息发送到同一个分区,从而保证单个分区内部保持消息顺序。
使用自定义分区器,确保业务标识路由到正确的分区
为了提高单个partition中的消费速度,我们可以使用java中的内存队列(blocking Queue)作为缓冲区,结合一步处理,提高消费端的速度。
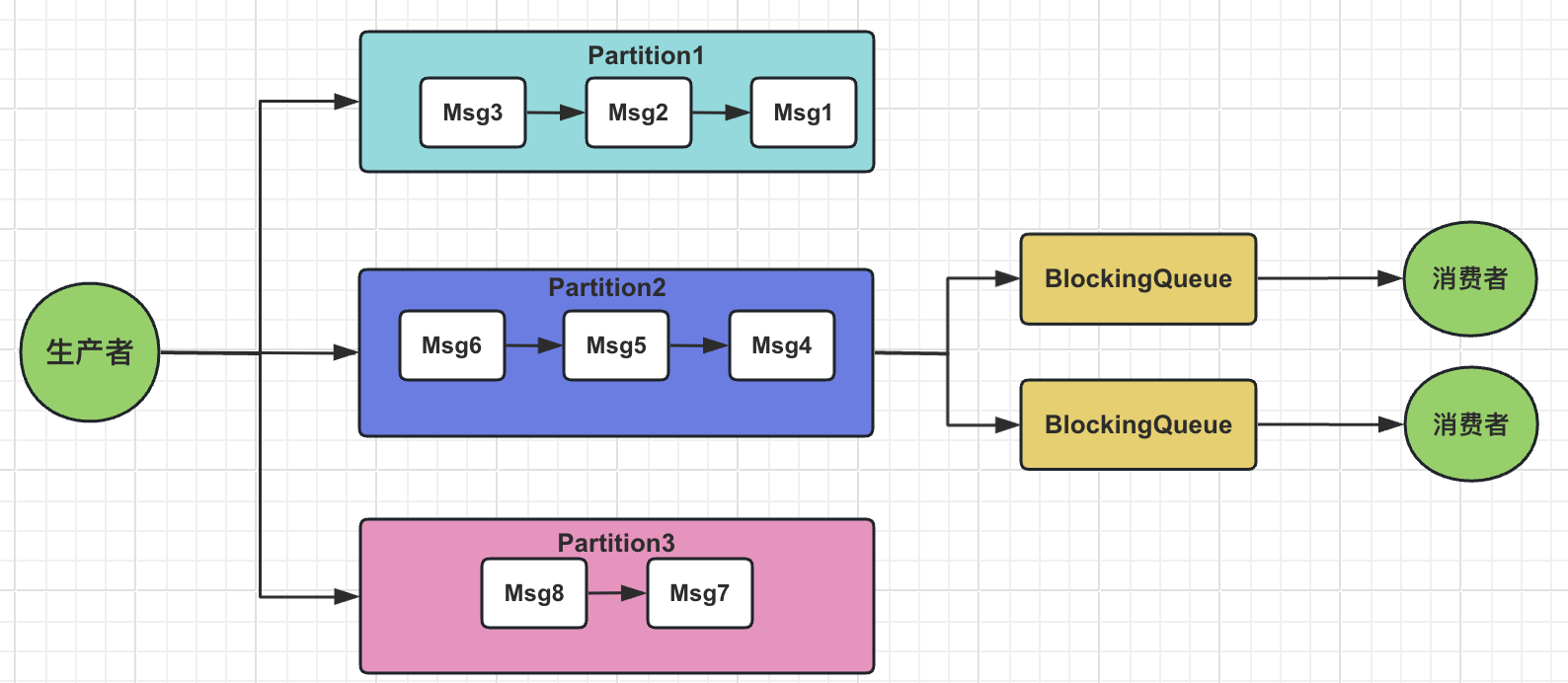
kafka消息丢失
Producer
producer丢失消息发生在客户端
为了提升效率,producer会将多个请求进行合并发送,合并的请求先放到buffer中,然后我们按照时间间隔将buffer中的数据发出。
正常情况,kafka提供了callback来处理消息发送失败或者超市的情况
一旦producer被非法停止,那么buffer中的数据将丢失
可以将buffer移到磁盘,在添加一个生产线程,相当于添加一个更加富裕的缓冲
Consumer
consumer消费方式有两种
自动提交,automatic offset commiting
手动提交,manual offset commiting
存在问题: 自动提交是根据一定的时间间隔,如果接受到的消息commit,commit提交和消费的过程异步,导致commit已经提交,此时消息进行丢失
可以改为手动提交,确保所有消息消费完毕后,才进行commit
broker
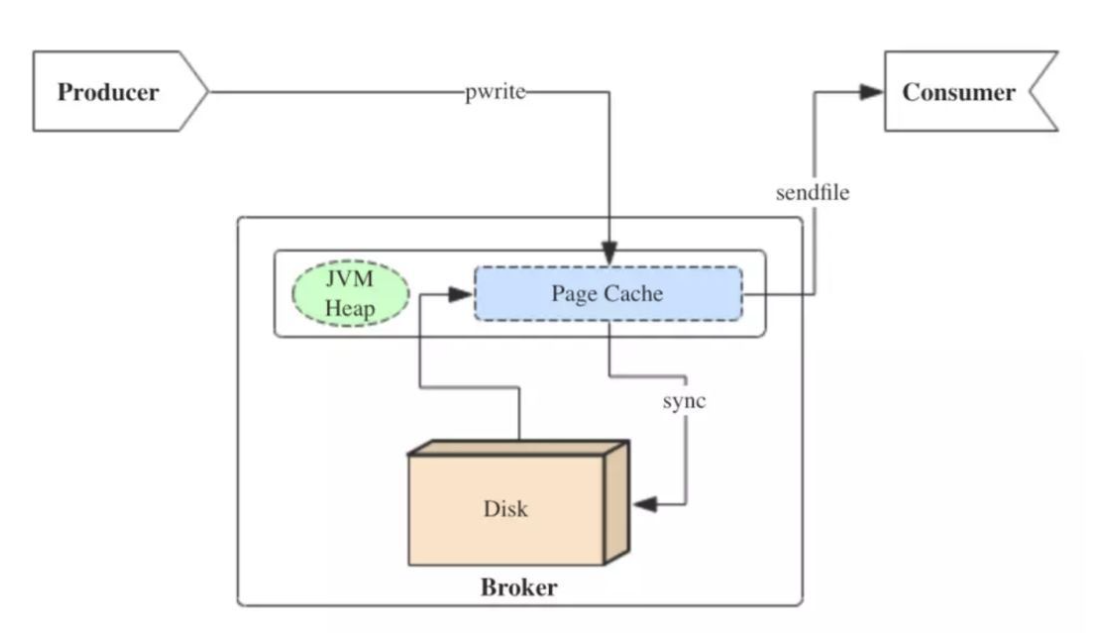
broker消息丢失是由于kafka为了得到吞吐量和更高的性能,将数据异步批量的存储在磁盘中,kafka采用了按照一定消息量或者按照一定的时间间隔进行刷盘
producer和broker之间采用一种协商机制,如果producer检测到broker消息丢失,就进行retry。这个检测消息丢失的过程就是使用ack机制,类似tcp的三次握手
acks = 0,producer不等待broker的响应,效率最高,但是消息可能丢失
acks = 1,producer和leader broker进行消息确认,不等待follower响应,此时leader成功写入page cache,会进行返回ack,如果还没有进行同步follower,那么消息就会丢失
acks = -1 / all,leader会等待ISR返回成功后才返回ack,安全性最高,效率最低
数据从leader同步到follower的过程
- 数据从pageCache被刷盘到disk。因为只有disk中的数据才能被同步到replica。
- 数据同步到replica,并且replica成功将数据写入PageCache。在producer得到ack后,哪怕是所有机器都停电,数据也至少会存在于leader的磁盘内。
消费重复
这个问题由于consumer的消息丢失我们会采取一种manual offset commit的操作,会导致一种情况,消息被消费,但是offset没有被提交,下次会导致重复消费
解决方案: 做幂等性校验
- 先写数据库,根据主键查一下,如果这数据存在,就update
- 先写redis,用set结构去重
- 在进MQ之前,需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似订单 id 之类的东西,当开始消费的时候,先根据这个 id 去比如 Redis 里查一下,如果没有消费过,这个 id 写 Redis。如果消费过了,那不处理了,保证别重复处理相同的消息即可。
- 设置唯一索引去重
- wechat
- Alipay