Kafka PageCache原理
pagecache
回顾我的zerocopy的文章,我们可以发现,其中第一步都是需要先把磁盘文件数据拷贝到内存缓冲区,这个内存缓冲区就是pagecache
由于零拷贝使用到了pagecache,所以零拷贝技术的性能得到了进一步的提升。
读写磁盘的速度相比于读写内存的速度慢太多,所以我们应该把读写磁盘替换成读写内存。
但是我们知道读写内存具有局限性,pagecache就使用了预读的功能,读磁盘数据的时候,如果read方法每次只读前32k的内容,但是内核会把32~64kb的字节也读取出来
这时候,pagecache的优点有两个:
- 缓存最近呗访问的数据
- 预读功能
kafka
kafka重度依赖于底层操作系统的pagecache的功能
kafka为什么不自己管理缓存,而是使用pagecache,理由如下:
- JVM中一切皆对象,数据的对象存储会带来所谓object overhead,浪费空间;
- 如果由JVM来管理缓存,会受到GC的影响,并且过大的堆也会拖累GC的效率,降低吞吐量;
- 一旦程序崩溃,自己管理的缓存数据会全部丢失。
我们来看一下kafka的两大核心组件如何引入cache的功能的
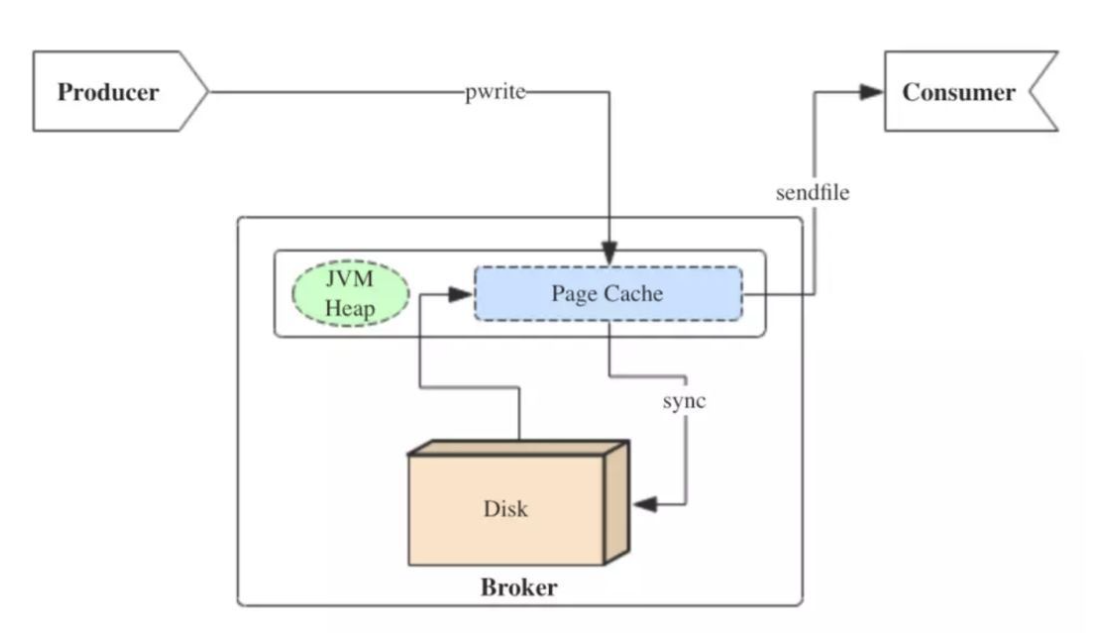
当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。
我们来看一下美团技术团队的图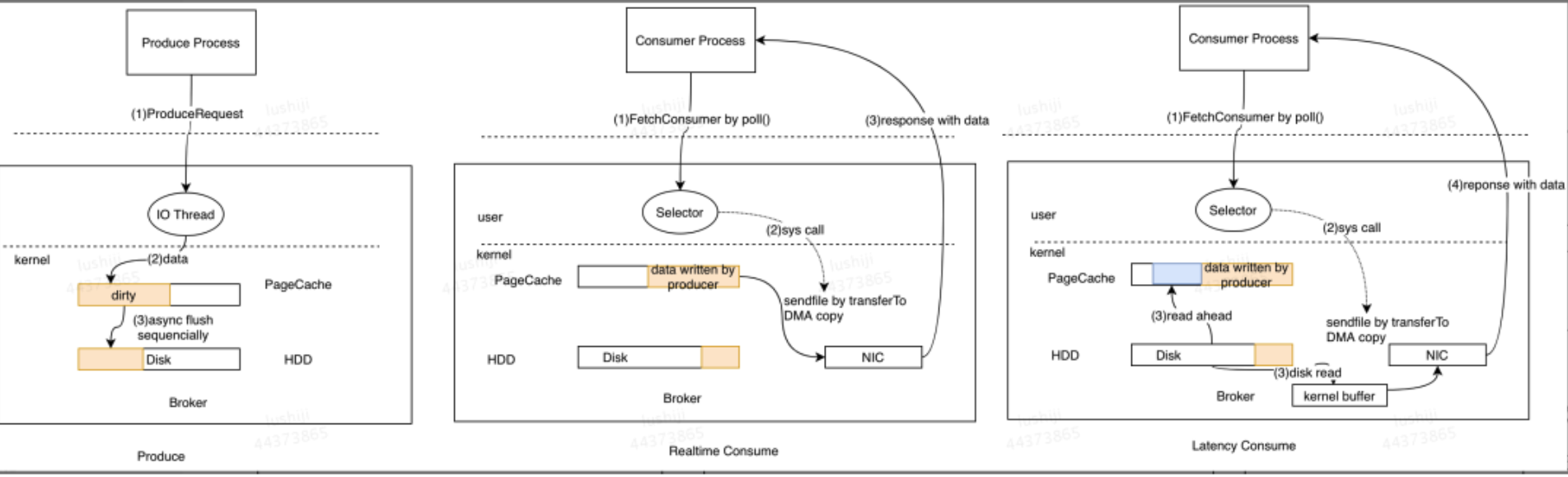
我们可以从图中获取到以下的信息
对于Produce请求:Server端的I/O线程统一将请求中的数据写入到操作系统的PageCache后立即返回,当消息条数到达一定阈值后,Kafka应用本身或操作系统内核会触发强制刷盘操作(如左侧流程图所示)。
对于Consume请求:主要利用了操作系统的ZeroCopy机制,当Kafka Broker接收到读数据请求时,会向操作系统发送sendfile系统调用,操作系统接收后,首先试图从PageCache中获取数据(如中间流程图所示);如果数据不存在,会触发缺页异常中断将数据从磁盘读入到临时缓冲区中(如右侧流程图所示),随后将数据拷贝到网卡缓冲区中等待后续的TCP传输(数据拷贝利用DMA操作减少拷贝次数和上下文切换)。
由此我们可以得出重要的结论:如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。并且Kafka持久化消息到各个topic的partition文件时,是只追加的顺序写,充分利用了磁盘顺序访问快的特性,效率高。
同时上面我们可以看到的是利用了操作系统中的zerocopy and poll()技术,这两个技术的详细使用我们可以在我的操作系统篇看到
 wechat
wechat- Alipay