聊聊消息分布式事务之柔性事务
分布式事务
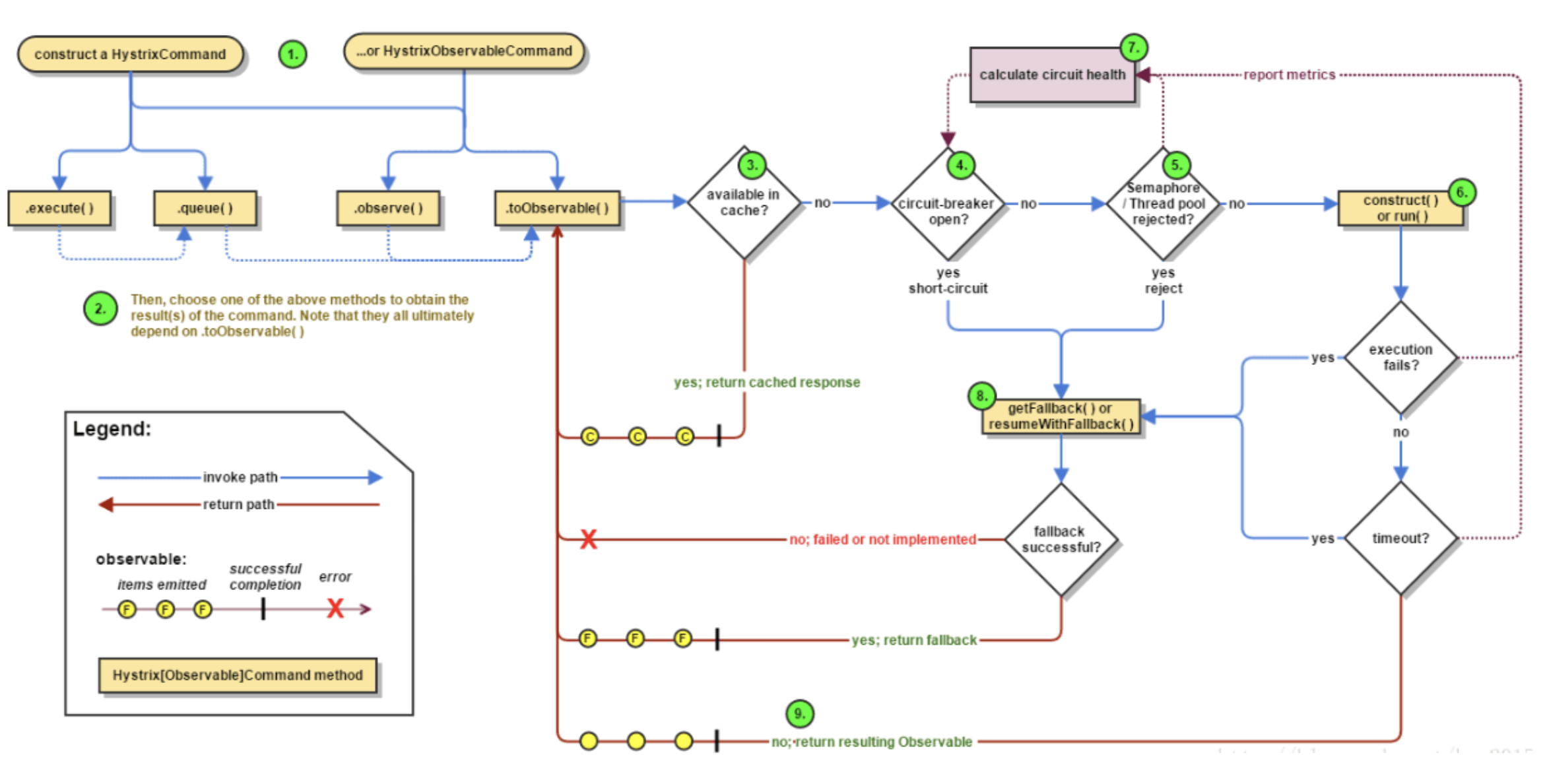
分布式事务之体系梳理
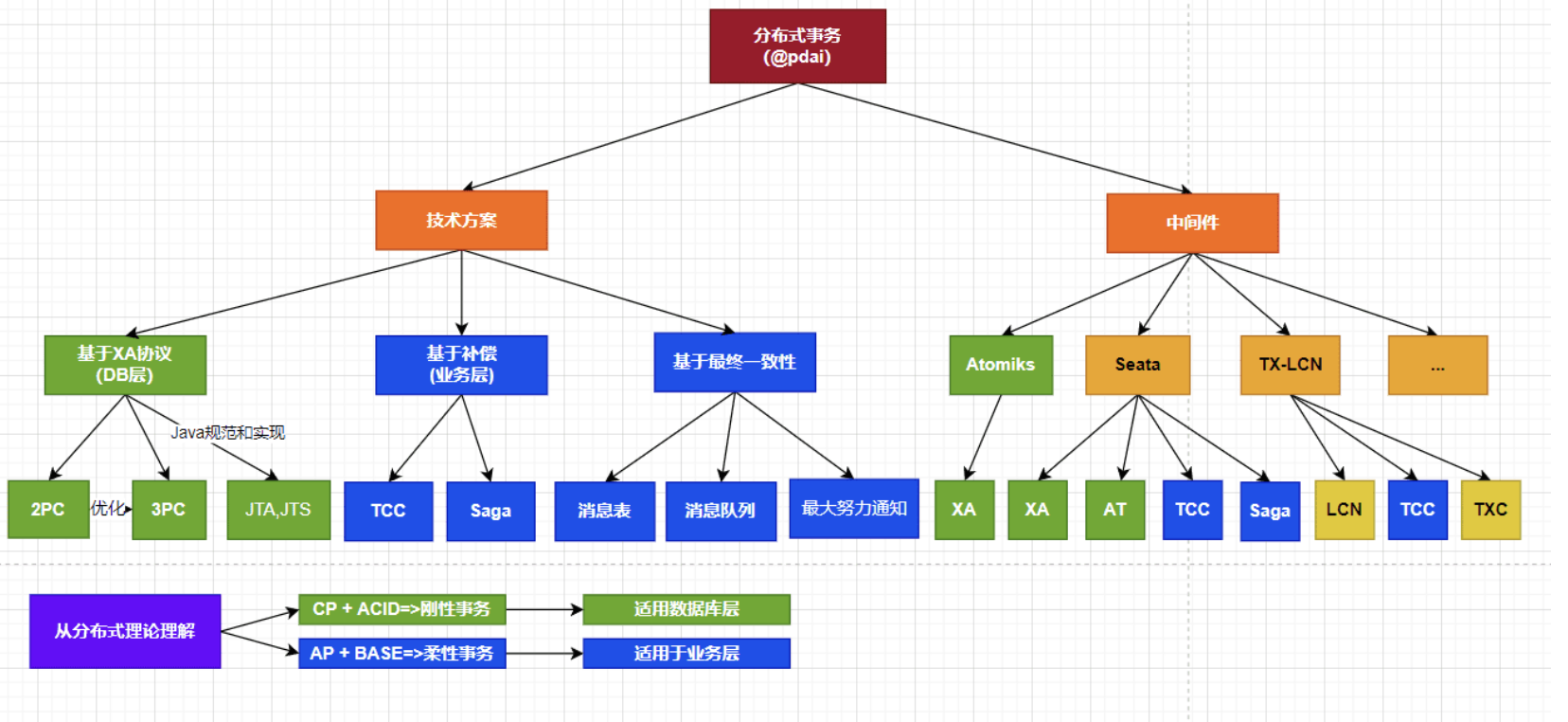
通过 @pdai 总结的体系图,我们可以发现技术方案的选择可以分为以下几种:
基于 XA 协议(数据库层面):
- 适用于需要保证一致性和分区容错性的场景。
- 遵循 ACID 理论,通常称为刚性事务。
- 常见实现方式包括二阶段提交(2PC)和三阶段提交(3PC)。
基于补偿(业务层面):
- 适用于需要保证可用性和分区容错性的场景。
- 遵循 BASE 理论,通常称为柔性事务。
- 常见实现方式包括 TCC(Try-Confirm/Cancel)和 SAGA 模式。
基于数据一致性(柔性事务):
- 通过最终一致性来实现。
- 使用消息表(本地消息表)和消息队列来实现最终一致性。
- 通过最终努力通知对消息队列进行进一步优化。
根据 CAP 理论,一致性、可用性和分区容错性,我们可以总结出:
- 如果需要保证 CP(一致性和分区容错性),同时遵循 ACID 理论,这就是刚性事务,通常需要遵循 XA 协议。
- 如果需要保证 AP(可用性和分区容错性),同时遵循 BASE 理论,这就是柔性事务,通常通过业务层的 TCC+SAGA 或最终一致性来实现。
分布式事务之刚性事务
本篇文章重点需要关注的是刚性事务的技术方案。
本地消息表
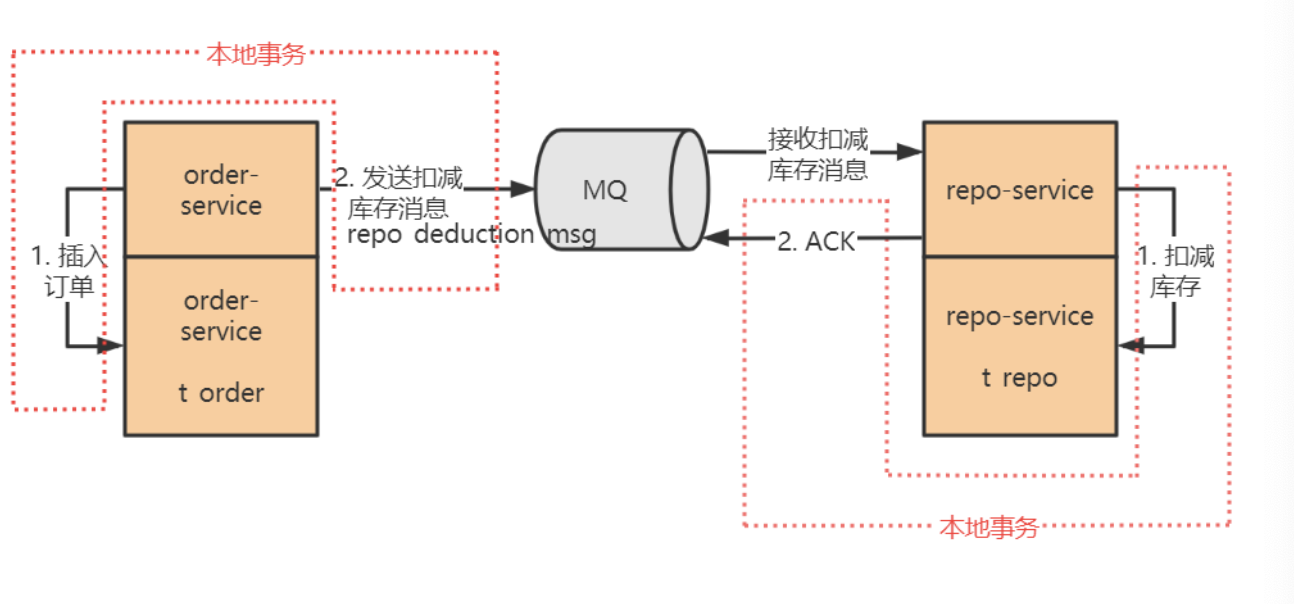
本地消息表的方案最初是由 eBay 提出,核心思路是将分布式事务拆解成本地事务进行处理。
整体的流程图:
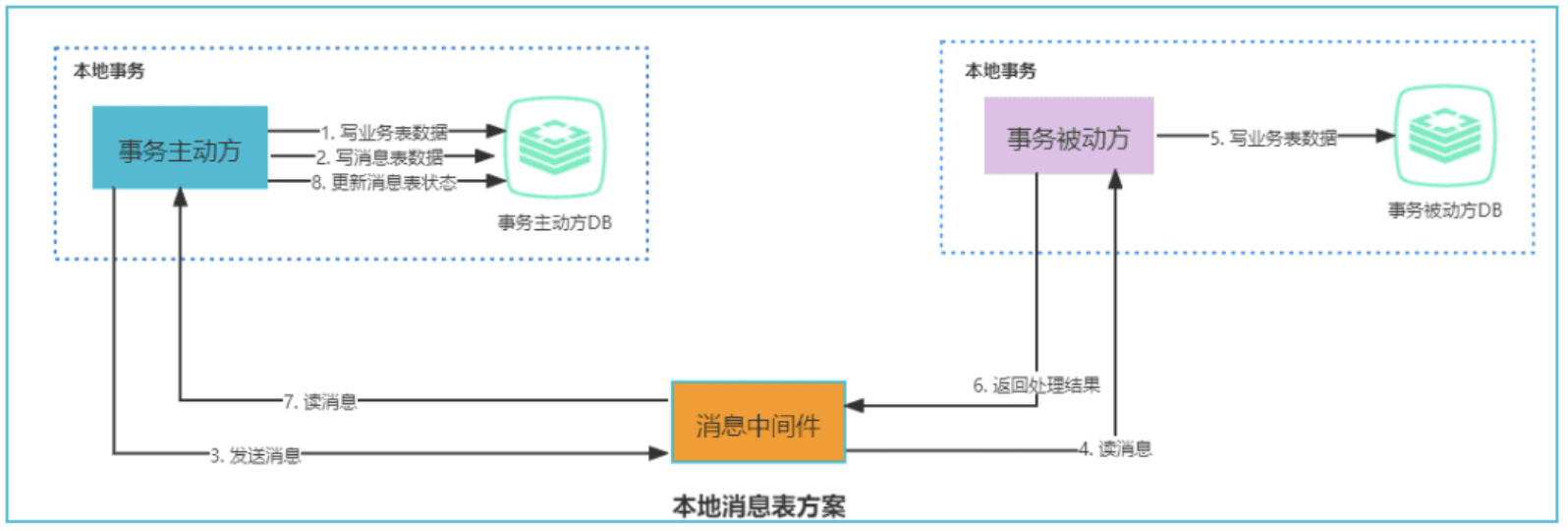
维护一张本地消息表的主要作用是确保分布式事务的一致性,避免因消息丢失或处理失败导致的数据不一致问题。其核心思想是通过本地事务保证业务和消息的原子性,并利用消息中间件进行异步通知和事务补偿,主要作用如下:
- 解决分布式事务一致性问题
在分布式系统中,事务的主动方和被动方通常位于不同的服务或数据库中,如果直接依赖消息队列进行通知,可能会出现以下不一致情况:
- 业务处理成功,消息发送失败。
- 事务主动方的业务操作已完成,但消息未成功发送,导致事务被动方无法感知该事务,从而导致数据不一致。
- 业务处理失败,消息却已发送成功。
- 事务主动方的业务操作失败回滚,但消息队列中的消息已经被消费,事务被动方已执行事务,导致数据不一致。
本地消息表的作用:
- 事务主动方在本地事务中同时处理业务逻辑和写入消息表,保证这两者的原子性,即要么一起成功,要么一起失败。
- 之后,轮询本地消息表,通过消息队列通知事务被动方处理事务。
- 事务被动方消费成功后,通知事务主动方,事务主动方更新本地消息表的状态。
- 可靠消息最终一致性
本地消息表提供了可靠消息(Reliable Messaging)的保障,即使发生异常情况,也能保证最终一致性:
- 事务主动方的业务逻辑和消息存储在本地事务中,避免丢失消息。
- 如果消息发送失败,轮询机制可以进行重试,确保消息最终能够被成功投递。
- 事务被动方处理消息失败时,可以再通知事务主动方进行回滚。
- 事务主动方可以通过事务被动方的确认,更新消息表的状态,确保所有消息被正确处理。
- 降低对 MQ 的依赖
如果直接依赖 MQ 进行事务处理,会出现:
- 消息可能在 MQ 传输过程中丢失,导致事务不一致。
- 依赖 MQ 的事务特性(如 RocketMQ 的事务消息),增加了架构复杂性。
本地消息表的方案将消息的可靠性托管给数据库,仅用 MQ 作为异步传输工具,即使 MQ 异常,系统仍然可以通过数据库存储和轮询机制恢复。
- 轻量级、易实现
相比于复杂的分布式事务(如 XA 事务、TCC),本地消息表方案更加轻量级:
- 只需要在事务主动方的数据库中维护一张本地消息表。
- 采用定时轮询+MQ的方式,不依赖于数据库的分布式事务能力。
缺点
- 与业务耦合度高:本地消息表需要与业务表放在同一个数据库中,适用于单体服务或简单微服务架构,但对于复杂架构可能需要额外优化。
- 消耗数据库资源:消息表存储在业务数据库中,会占用数据库的存储和计算资源。
- 轮询机制的效率问题:如果消息表数据量大,轮询频繁,会增加数据库负担。
总结
维护本地消息表的核心作用是解决分布式事务数据一致性问题,确保事务消息的可靠性,并通过轮询+MQ机制实现最终一致性,是一种轻量级、低耦合的可靠消息方案。
示例
场景描述:
- 订单服务(OrderService):负责创建订单,同时记录一条本地事务消息。
- 库存服务(RepoService):监听订单创建消息,扣减库存。
- 消息中间件(Kafka/RocketMQ):用于异步通知库存服务。
- 本地消息表(transaction_message):用于存储未成功发送的事务消息,并定期轮询重试。
创建本地消息表
1 | CREATE TABLE transaction_message ( |
下单操作
1 |
|
定期轮询消息表并发送消息
1 |
|
库存服务消费消息
1 |
|
消息确认
1 |
|
基于MQ的最终消息一致性
基于 MQ 的分布式事务方案其实是对本地消息表的封装,将本地消息表基于 MQ 内部,其他方面的协议基本与本地消息表一致。
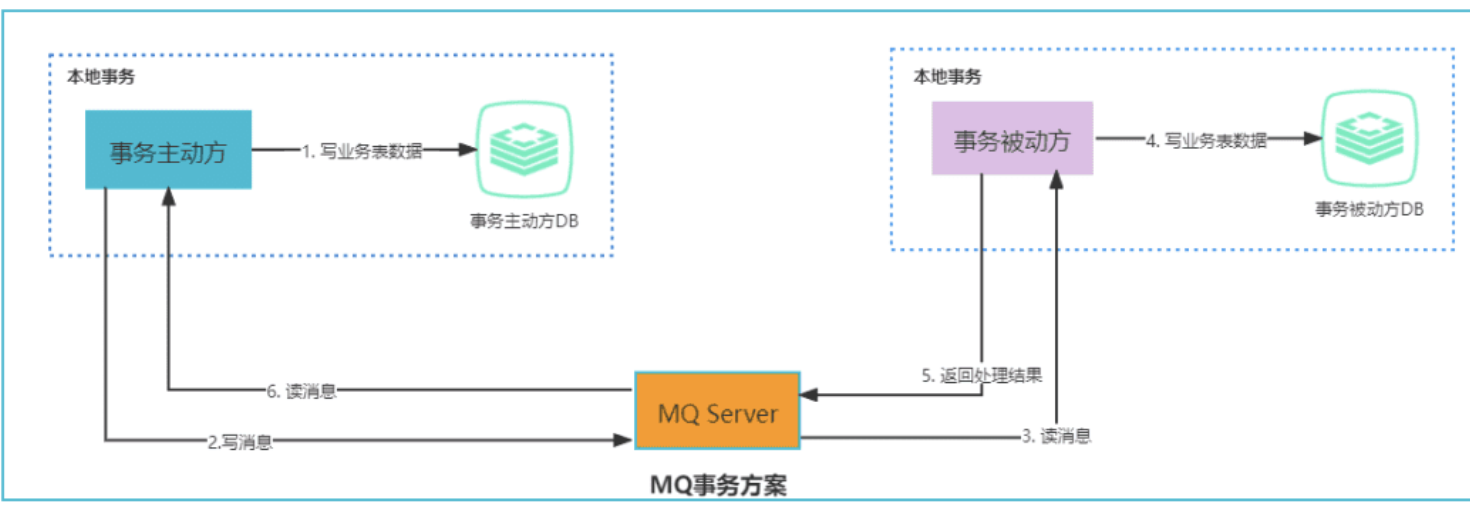
举例:
现在有一个支付网关,消费者点击下单之后需要首先扣除用户余额,其次需要更改合同状态,这时候 Kafka 如何实现最终消息一致性,通过两点:
Kafka 的 Exactly Once 语义(EoS)
Kafka 提供 Exactly Once Semantics (EOS),即保证消息处理的精确一次语义。消息的“精确一次”语义保证了消息在消费过程中不会丢失或重复。Kafka 提供的 Exactly Once 语义主要通过以下方式实现:
生产者端:幂等性(Idempotence)
- 在消息发送过程中,Kafka 保证生产者不会因网络故障、请求超时等导致消息的重复发送。通过为每条消息生成一个全局唯一的 ID 和确保顺序性,Kafka 避免了消息的重复发送。
消费者端:事务管理(Transaction)
- Kafka 支持生产者和消费者在事务内进行消息生产和消费。消费者可以通过事务 API 控制消息的提交和回滚,确保消费者在某个事务内消费消息时的一致性。
- 生产者在发送消息时,通过开启事务来控制消息的写入状态,只有当整个事务被提交时,消息才会被提交到 Kafka,并且消费者只有在事务提交后才会消费这些消息。
消费者的事务管理
- Kafka 消费者通过事务来确保消息处理的 Exactly Once 语义。消费者在消费消息时可以将多个消费操作(如批量处理、消息确认等)放在一个事务中,如果在消息处理过程中出现错误,事务可以回滚,确保消息没有被多次处理或丢失。
异常处理:消息回查与补偿机制
- 如果消息发送方发生了故障(如断网或服务崩溃),Kafka 会通过消息回查机制进行恢复。当生产者未收到提交确认时,Kafka 会向生产者发起回查请求,生产者需要根据其本地事务的执行结果进行确认。
- 如果生产者没有收到事务提交确认(如网络延迟或断网),则 Kafka 会再次尝试确保消息的最终一致性。
 wechat
wechat- Alipay