缓存一致性解决方案
Introduction
我们知道使用缓存可以加快数据的访问速度,但是如何更新缓存也随之成为了问题。更新缓存有四种模式:
- Cache Aside Pattern
- Read/Write Through Pattern
- Read Through
- Write Through
- Write Behind Caching Pattern
现在常见的解决思路是先删除缓存,然后再更新数据库,后续的操作会把数据装载到缓存中。
问题
有两个操作,一个更新,一个查询操作,这两个是并发操作。更新操作先进行删除缓存,接下来查询操作发现没有数据,会从数据库中读取数据,然后放在缓存中,但是接下来更新操作会去进行更新数据库。于是缓存中的数据一直是脏数据。
Cache Aside Pattern
具体的逻辑如下:
- 失效:先从 Redis 中读取数据,如果没有得到,就从数据库中读取数据,成功后,放入缓存中。
- 命中:应用程序从缓存中取出数据,然后返回。
- 更新:先把数据存入数据库中,成功后,再让缓存失效。
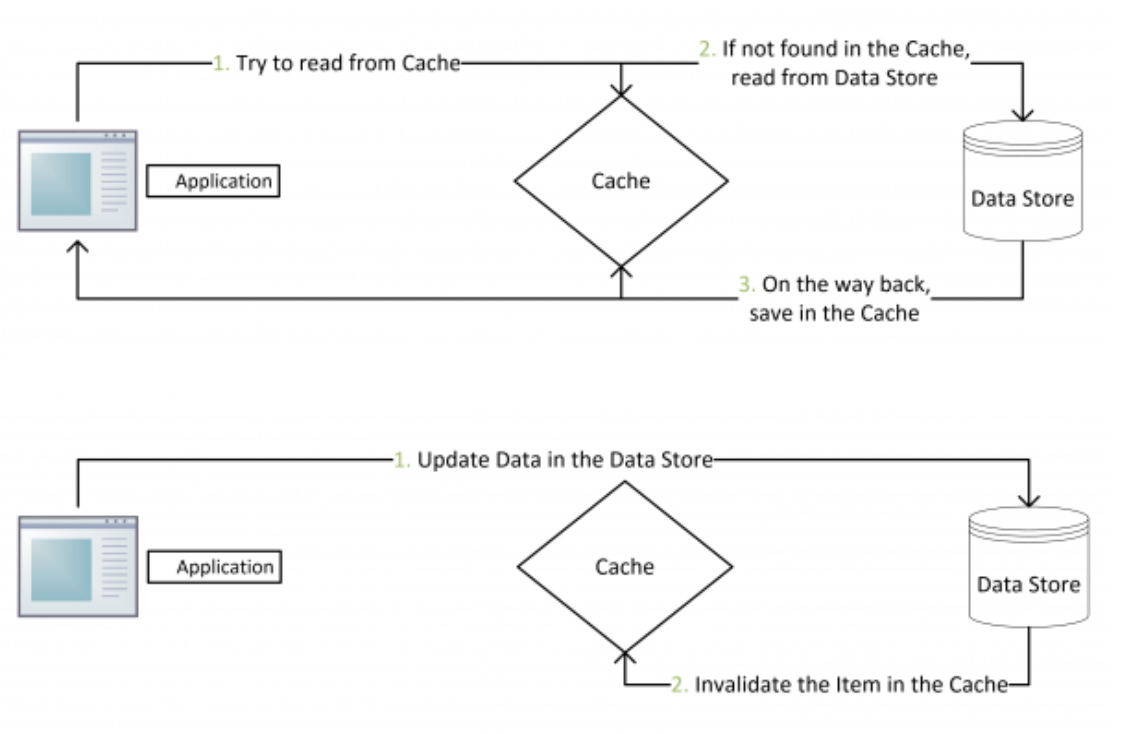
现在看一下如果一个更新操作,一个查询操作在并发情况下是否有问题。查询操作并不会去删除缓存中的数据,然后查询操作读取到一个老数据,更新操作更新完数据库后去使缓存中的数据失效,这时候,后续的查询操作就一直读取的是最新的数据了。
但是是否没有了并发的问题呢?答案是有的。如果一个查询操作,一个更新操作,如果查询的数据是空的,就会尝试去数据库中读取数据,此时我们再执行更新操作,更新操作使得数据库中的数据更新,并且使得缓存中的数据失效,此时查询操作姗姗来迟,将老的数据放入了缓存中。
理论上存在,如果要执行可以通过 2PC 来进行解决。或者降低并发时脏数据的概率。
Read/Write Through Pattern
在上面的模式中,应用代码需要维护两个数据存储。在 Read Through 中应用可以认为是单一的存储,自己维护自己的缓存。
- Read-Through:读取数据时,先查询缓存,若缓存命中,则直接返回数据;若缓存未命中,则查询数据库,并将数据写入缓存,以备后续使用。
- Write-Through:更新数据时,应用程序直接写入缓存,缓存再同步更新数据库,以保证缓存和数据库一致。
我们可以发现,写入频率较低时使用这种方案比较好。
Write Behind Caching Pattern
Write Behind 又叫 Write Back。一些了解 Linux 操作系统内核的同学对 Write Back 应该非常熟悉,这不就是 Linux 文件系统的 Page Cache 的算法吗?是的,你看基础这玩意全都是相通的。所以,基础很重要,我已经不是一次说过基础很重要这事了。
Write Back 套路,一句话就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的 I/O 操作飞快无比(因为直接操作内存嘛),因为异步,Write Back 还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道 Unix/Linux 非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性能是有冲突的。软件设计从来都是取舍 Trade-Off。
方案延伸
队列 + 重试机制在 Cache Aside 模式下解决缓存删除失败的问题。
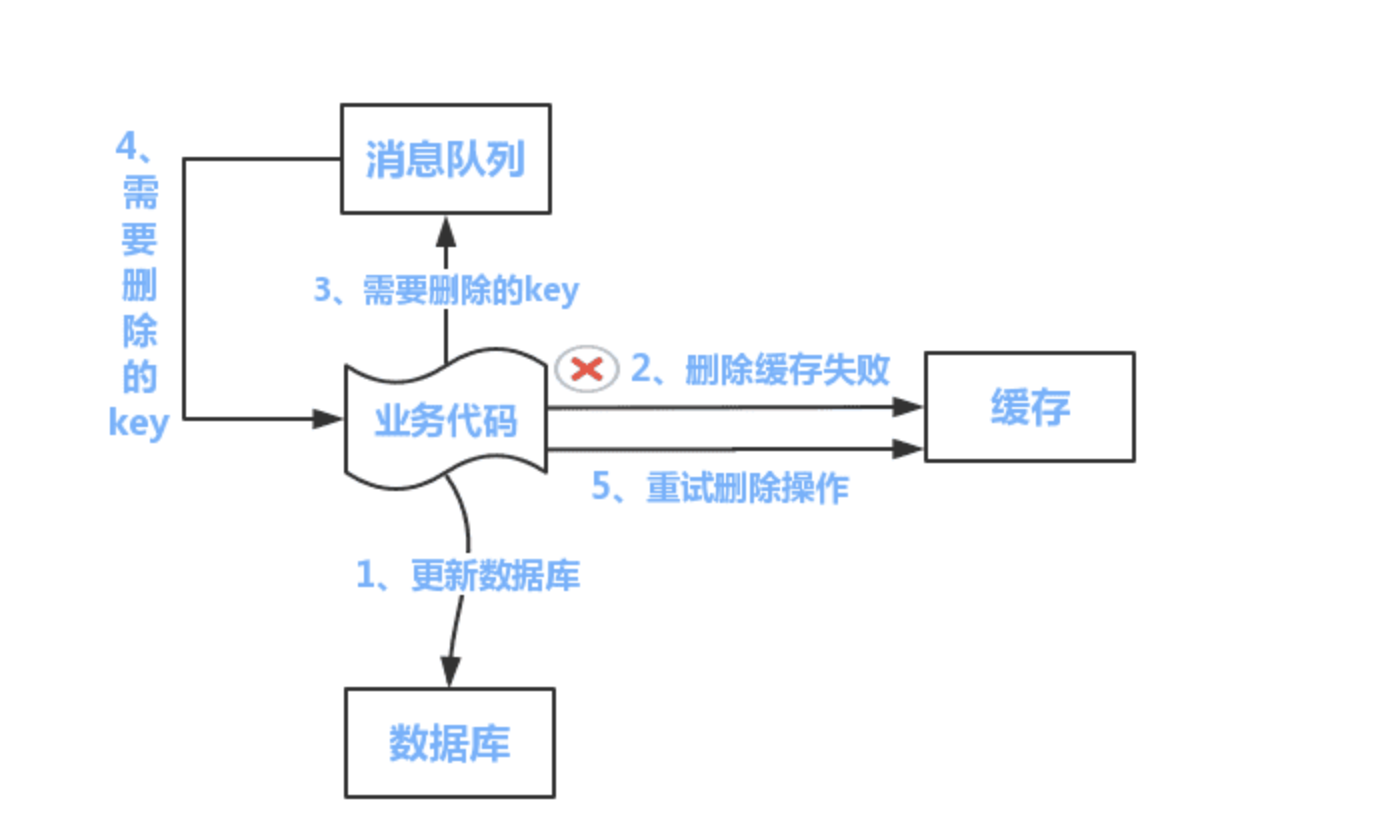
更新操作的流程如下:
- 更新数据库数据;
- 缓存因为种种问题删除失败;
- 将需要删除的 key 发送至消息队列;
- 自己消费消息,获得需要删除的 key;
- 继续重试删除操作,直到成功。
查询操作类似于 Cache Aside,查缓存,如果失败,就查数据库,然后更新缓存。
在 Read/Write Through Pattern 下异步更新缓存。
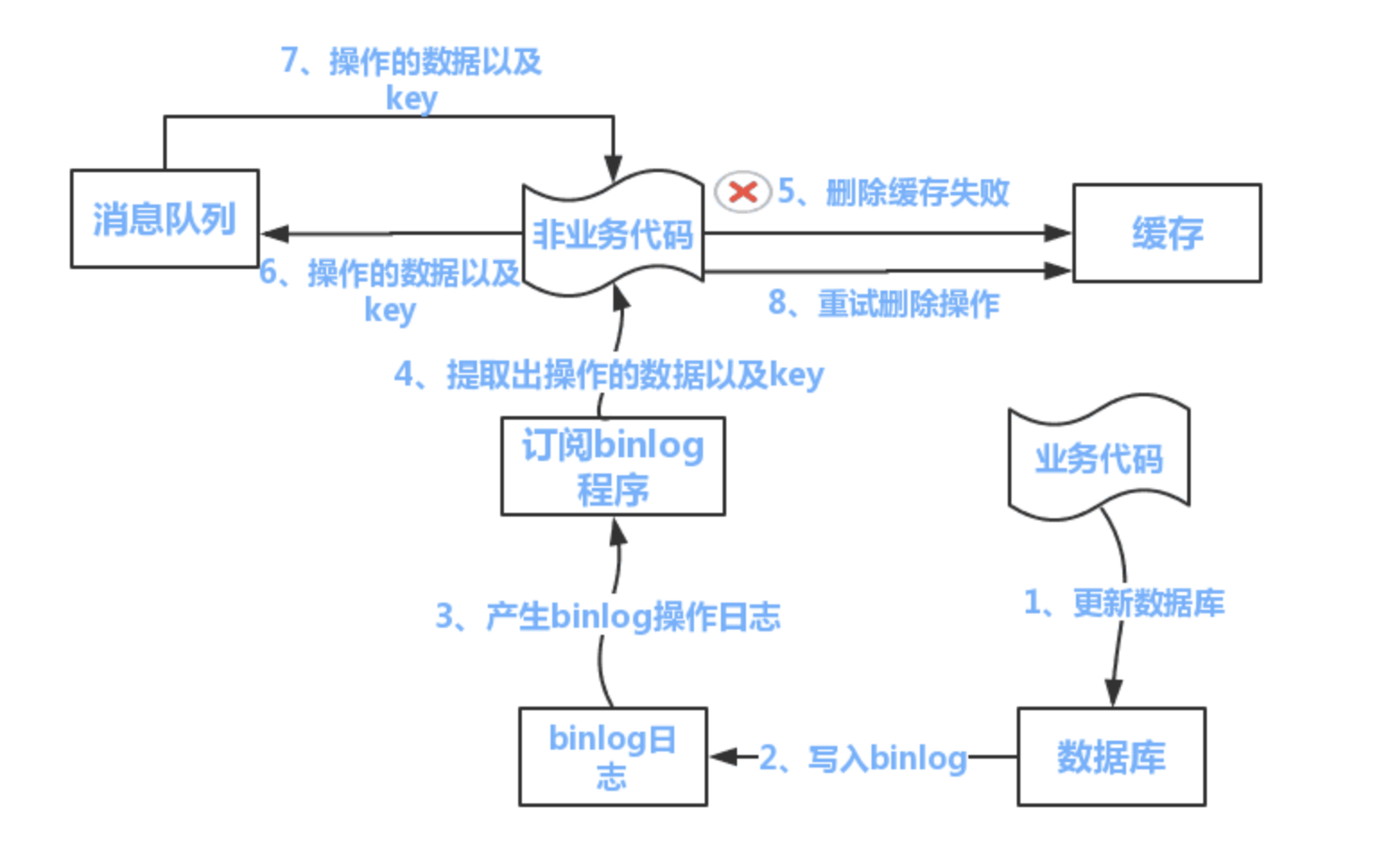
思路:
- 业务更新 MySQL(Insert、Update、Delete 操作)。
- 订阅 MySQL Binlog:
- 启动一个独立的订阅程序(如 Canal)。
- Canal 监听 MySQL 的 Binlog 日志,解析出数据更新操作。
- 异步更新 Redis:
- 通过 MQ(Kafka、RabbitMQ 等)推送变更消息。
- 另一个应用消费这些变更,执行对应的缓存更新(更新或删除 Redis 中的缓存)。
 wechat
wechat- Alipay